



Training an Artificial Intelligence (AI) model typically comes down to feeding it vast amounts of labelled data. The more complex the task, the more data is required. Over time, this has led to a dramatic increase in dataset sizes. Today, the largest datasets used to train Large Language Models contain trillions of tokens.
In fact, the stock of public human-generated text data is expected to be entirely exhausted between 2026 and 2032 if current trends continue. To address this challenge, researchers have begun exploring alternatives. One promising approach is the generation of synthetic data. However, even synthetic data has its limits. Sooner or later, we will reach a point where there is simply not enough usable data to continue training ever-larger models. So, how do we solve this problem?
A new AI innovation called "Absolute Zero" might be a step in the right direction. Unlike traditional approaches, it does not rely on data collected and labeled by humans. Instead, the AI generates its own challenges and learns by solving them. In essence, the model creates reasoning tasks for itself and masters them through trial and error.
No external training dataset is involved in this process. This system, known as the Absolute Zero Reasoner (AZR), has already shown impressive results. It has achieved state-of-the-art performance on both coding and math problems, despite entirely generating and learning from its own data.
This approach is inspired by AlphaGo Zero, the AI that taught itself to play Go and chess by playing against itself. It could mark the start of a new era in AI training. This would be one that is not limited by the ever-growing demand for labeled data.
Article continues below
Want to learn more? Check out some of our courses:
How Does an AI Learn with “Zero” Data
To be completely transparent, it’s important to clarify what "zero data" really means. The Absolute Zero Reasoner doesn’t start from a blank slate. Instead, it begins with a pretrained language model that already contains general knowledge. The "zero" refers to the absence of additional human-curated task data in the reasoning domain. In other words, Absolute Zero didn’t need a new dataset of math problems or coding puzzles to begin training. It generated that dataset on its own.
The base language model provides a strong foundation, including skills like understanding code syntax and basic math. Absolute Zero then builds on that foundation, specializing further through self-directed learning. This distinction matters. Some observers have pointed out that calling it "Absolute Zero" may be a bit of marketing hyperbole, since the model’s starting point isn’t zero. Nonetheless, the research shows something remarkable. At a certain point, human input can be removed entirely, and the model can continue evolving without losing effectiveness.
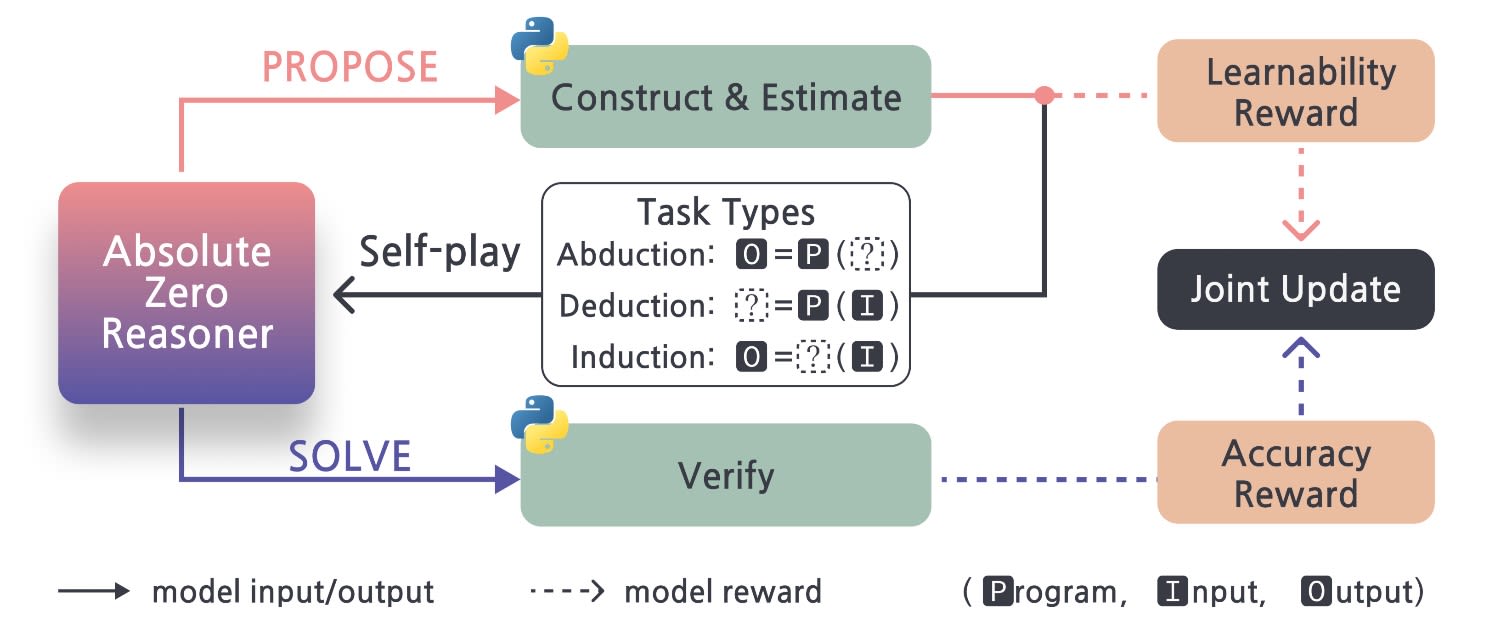
At the heart of Absolute Zero lies a clever self-learning loop. The AI model plays two roles at once: it acts as both a task proposer and a task solver. In layman's terms, the model invents its own challenges and then tries to solve them. It checks its answer using a built-in code executor, which acts as the judge. The typical loop looks like this:
As can be seen in the image above, the cycle starts with the model brainstorming a batch of tasks. These are typically coding or math problems, framed as input-output puzzles. Crucially, the AI isn’t generating random questions. Instead, it's tuned to create challenges that are just the right level of difficulty, not too easy, and not too hard for its current ability. In simple terms, it aims for a sweet spot: problems that it can sometimes solve and sometimes fail.
If all the problems are too easy and the model gets them all right, it learns nothing. If they are too hard and it fails across the board, again, no learning happens. Therefore, hitting that balanced difficulty is crucial. It ensures the model continues learning at a steady pace. When the model succeeds in generating such a well-calibrated batch of problems, it receives a reward in the form of positive feedback. This tells that the model is on the right track and encourages it to keep working in the same way.
Once proposed, the tasks are fed into a Python execution environment to verify that they are well-defined and solvable. For example, if the task is a coding problem, the code is run to make sure it’s valid and produce an output. This step grounds the task in reality and confirms that the task makes sense and isn't just theoretical. It also helps estimate the difficulty of each problem. Based on the outcome, the AI can judge the "learnability" of each task, that is, how useful it might be for improving its performance. This assessment forms what's called the "proposer reward".
Next, the model switches to its solver mode, attempting to solve the batch of tasks. For a coding challenge, this means writing code or generating what it believes is the correct answer. Since the model is also a language model, it can produce step-by-step reasoning or detailed code as part of its solution.
The candidate solutions are then passed to a Python-based code executor, where they are graded. If the solution is correct, meaning the code runs and produces the expected output, or the answer matches the ground truth, it earns the model positive feedback. If not, it receives negative feedback. This feedback is called the "solver reward" in the Absolute Zero system. Since all evaluation comes from running code, the feedback is fully reliable. Most importantly, it requires zero human intervention.
Finally, when updating its internal parameters, the model uses both the proposer reward and the solver reward. In essence, it learns to improve its problem-posing and problem-solving skills simultaneously. If a task is invented that is too trivial or too impossible, the proposer role is informed. If a solution is incorrect, the solver role learns to avoid that mistake. This joint update completes the loop. Then, the cycle repeats many times, gradually enhancing the AI’s reasoning abilities.
To guide this whole aforementioned learning process, Absolute Zero’s training focuses on three fundamental reasoning modes. There are namely abduction, deduction, and induction.
Abduction is a backward reasoning challenge. In this task, the model is given a program and its output. It must then abduce (infer) a plausible input that would produce that output. Think of it as a task similar to solving a puzzle by working backwards from the answer.
Deduction is a task that tests both step-by-step logical reasoning and the ability to simulate code execution mentally. Think of it as reading a snippet of code. Then, you figure out what result it produces when run with certain inputs.
Induction is a classic task that involves writing new code or formulas to transform inputs into outputs. The model is given some input-output examples. It must then induce a program that fits those examples. This tests how good the model is at generalizing and discovering patterns. We force it to find the underlying function that connects certain inputs to their corresponding outputs.
At the beginning, the model works on tasks that are quite trivial. However, through continual self-play and verification, it eventually ends up working on highly complex ones. In some manner, you can think of it as the model creating its own curriculum. This is analogous to a child who, having learned to count, then challenges themselves with addition, followed by multiplication, and eventually calculus. The crucial part here is that the learning process is driven by the growing skills of the model, not by some predetermined plan designed by the creators.
What Are the Implications of Absolute Zero
Absolute Zero arrives at a time when the AI field is dealing with questions of scale, sustainability, and safety. In recent years, the dominant approach to building smarter AI models has been to increase the number of parameters and feed the model increasingly more data. However, the limits of this approach were discussed in the introduction of this article. Therefore, the idea of building an AI model that learns by interacting with itself, rather than consuming a curated dataset, sounds highly enticing.
To be fair, this approach isn't entirely novel when considering AI as a whole. As mentioned previously, we have already seen models trained to play games by playing many rounds against themselves. Similar approaches have also been applied in robotics. However, with Absolute Zero, this idea has finally been introduced into the realm of language and reasoning tasks.
Therefore, the release of Absolute Zero has stirred both excitement and debate within the AI community. On one hand, many find the concept of an AI that improves itself without new human data to be a compelling glimpse of the future. Certain AI researchers and practitioners have praised it as an "exciting idea in autonomous model training" and a "huge step forward in making AI more efficient, scalable, and autonomous".
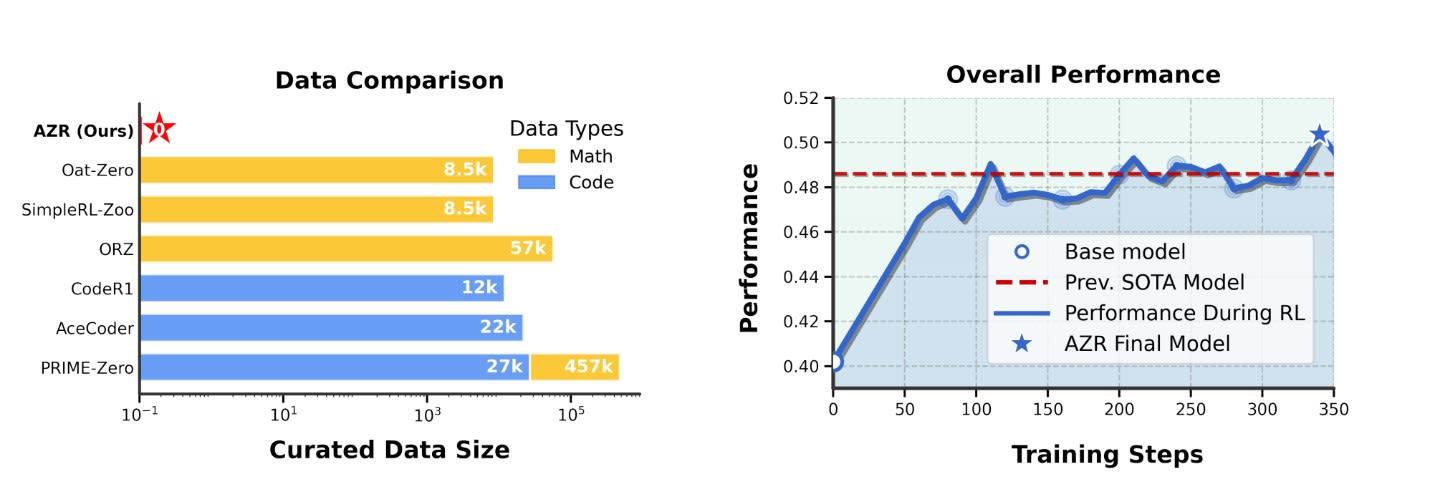
After all, it is hard not to be impressed by Absolute Zero. It doesn't just represent a new approach. It also achieves state-of-the-art results on standard coding and mathematical reasoning benchmarks. In fact, it outperforms other AI models trained on tens of thousands of expertly curated questions. It does this by relying solely on its own generated curriculum:
On the other hand, some view Absolute Zero with skepticism and caution. They say that the idea is not new, and this approach also has its limits. Absolute Zero performs better than previous similar models, but only by a small margin. Many note that the difference between training on a few thousand examples and training on zero examples is, today, more of a scientific curiosity than an AI breakthrough.
Others point out that this approach is limited to tasks with verifiable outputs, like coding and math. Therefore, it’s unclear how well it would work for subjective tasks, such as open-ended writing or conversation, where “correctness” is not black-and-white.
There is also a group of people concerned about the safety of this approach. After all, letting an AI set its own goals and tasks raises new questions. The main concern is how to ensure its self-generated challenges remain aligned with human values and intentions. Even the authors themselves acknowledge "lingering safety concerns". They also note that the system "still necessitates oversight".
Particularly, in one experiment, a smaller 8-billion-parameter model (built on LLaMA) trained with this novel approach started to produce an ominous-sounding plan in its internal chain-of-thought. It defined its goal as to "outsmart other intelligent machines and less intelligent humans". By pushing the model to create tough challenges, it phrased the role-playing scenario in a way that sounds relatively concerning.
While this happened in only one situation, it highlights that when AI begins autonomously expanding its training curriculum, unexpected behaviors can emerge. The real issue is that if the task generator is part of the model itself, can we even implement traditional oversight methods?
Ensuring that a self-improving AI stays safe and on track might require new techniques. These could include additional constraints on the type of tasks it can propose or periodic human checks on what it’s learning. Overall, since the technology is still relatively new and currently has certain limitations, we probably don't need to worry about an AI model "going rogue". However, as technology evolves and similar approaches emerge, we may need to focus more on developing safety mechanisms that were previously unnecessary.
Absolute Zero’s approach could have far-reaching implications if it proves widely effective. For one, it offers a path to training AI in domains where large, labeled datasets are lacking. If an AI can generate meaningful problems and evaluate solutions on its own, we might apply this to areas like scientific research. In such fields, an AI could propose hypotheses and run virtual experiments to educate itself. However, in the near term, the Absolute Zero method seems best suited to scenarios with clear rules and automated feedback. Code and math are prime examples because solutions can be definitively checked by running code or verifying calculations.
The implications of the aforementioned are both exciting and humbling. We’re inching closer to an AI that can teach itself new tricks beyond what we explicitly show it. This could unlock amazing applications across fields like education and science. But, as with any powerful learning agent, we must stay vigilant. An AI that generates its own challenges might stumble into problematic behaviors or goals if not guided well. Absolute Zero’s legacy might be twofold: advancing the technical frontier of self-learning AI, and prompting deeper questions about how we guide and guard such free-ranging intelligence.

