


When the first modern Large Language Models (LLMs) were released, they served more as a tech demo than a practical tool. Some professionals, such as copywriters, immediately found ways to incorporate them into their workflows. However, most companies had no clear method to harness their full potential or integrate them into existing pipelines for financial gain. As more advanced models emerged, it became clear that LLMs were not just a novelty. Finding efficient and strategic ways to use them started to appear beneficial and essential. In the future, the ability to leverage these models effectively may determine a company's ability to stay competitive.
Beyond improvements in reasoning and complex problem-solving, a major breakthrough came with the development of Retrieval Augmented Generation (RAG) pipelines. These allowed LLMs to consult external databases before generating a response. By enriching user queries with additional information collected from these databases, RAG systems significantly increased model accuracy.
For the first time, LLMs could draw on fresh, context-specific data, rather than relying solely on what they were originally trained on. However, even RAG systems hit limitations. While they could retrieve and use new information effectively, they still didn't approach problem-solving in a way that resembled human thinking. That gap led to the next evolution in the field: AI agents.
- Introduction to RAG: Retrieval Augmented Generation
- How to Create an Effective Roadmap for Your RAG System
In this article, the first in our series on AI agents, we will cover the fundamentals, explaining everything you need to know to gain a complete understanding of the nature and function of AI agents. In subsequent articles, we will focus on demonstrating how these agents are created. We will cover the many frameworks currently available to construct custom AI agent systems.
What Are the Advantages of Using AI Agents Over Traditional Approaches
As mentioned in the introduction, AI agents represent the next evolutionary step of RAG systems. They build on the idea of enabling LLMs access to additional material and helping them solve more complex problems. But first, let's explore the actual benefits of using AI agents compared to standard RAG systems.
Imagine an LLM-based application designed to assist marketing professionals in evaluating a brand's digital performance. With a well-constructed RAG pipeline, analysts can ask direct questions like, “What was Brand Y’s total social media engagement in Q1 2023?”, and receive accurate answers from an LLM. This approach closely mirrors how an experienced marketer would extract data from a detailed analytics report.
However, the work of marketing professionals is rarely as simple as that. When analyzing a brand's performance, they often need to collect key insights from data, for example, how a recent digital campaign impacted brand engagement. In addition, they need to use those insights to determine which strategies to prioritize in the future to further boost customer engagement.
Answering questions like these requires more than simply pulling data from a dashboard. It calls for a system capable of planning, identifying relevant information, maintaining context, utilizing various analytical tools, and breaking down complex questions into manageable sub-tasks. These combined capabilities form the foundation of what we now call an LLM Agent.
What Are AI agents
Based on what was discussed in the previous section, we can offer a straightforward definition of AI agents. In the modern era, AI agents are advanced AI systems that autonomously interpret instructions, make decisions, and take actions to achieve specific goals. The "brain" of these systems is a Large Language Model (LLM). However, a standard LLM is primarily designed to generate answers to questions.
LLM agents, by contrast, possess advanced reasoning capabilities and memory. They utilize tools beyond the LLM itself to perform multi-step tasks that go far beyond simple conversation. Early projects that aimed to create such systems include AutoGPT and BabyAGI. To better understand how these systems function, let's break down an LLM-powered AI agent into its core components.
All of these components function in a feedback loop. Essentially, the agent uses its own outputs as new inputs throughout the process. After being tasked with solving a problem, the agent plans its approach and executes the first action it determines. Once the initial action produces an output, that result is now observable, either through tools or user feedback. It also enables the agent to continue with the following steps in its planned process. This looping behavior continues until the agent completes all planned tasks and signals the conclusion of the entire process.
Article continues below
Want to learn more? Check out some of our courses:
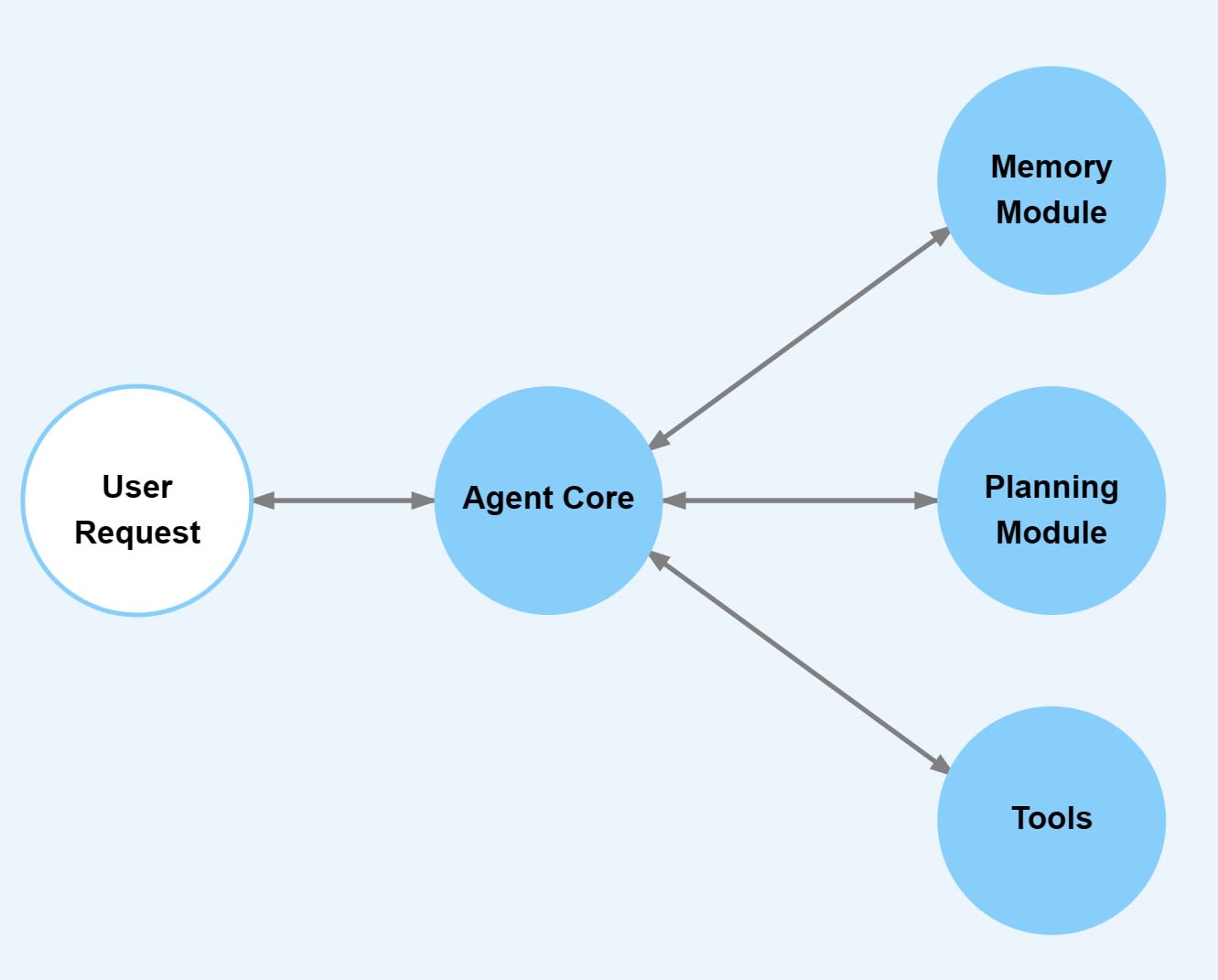
What Is the Agent Core
The agent core acts as the "brain" of the system. It serves as the central hub, managing the core logic, behavior, and decision-making processes of the agent. Think of it as the executive center that synchronizes all internal operations, enabling the agent to function autonomously. When designing the agent core, we typically follow a template and define the following elements:
- Primary objectives
- Available execution tools
- Strategies and guidelines
- Contextual memory capability
The first step in designing an agent is to define its objectives. This includes setting the agent's priorities and determining the factors that guide its decision-making. For example, if an agent is tailored for customer support, its objectives might involve reducing response times, delivering accurate information, and maintaining a professional tone. These goals help the core decide which actions and tools best support the desired outcomes.
Next, we define the available execution tools. These serve as a form of "user manual" for the agent's capabilities. Each tool acts as an interface to an external service, such as conducting web searches, performing calculations, or retrieving data. The core not only identifies the tools at its disposal but also understands the specific contexts in which each tool is most effective. This enables the agent to dynamically select the appropriate tool for each task.
Embedded within the core are detailed instructions on how to implement various planning methods. These strategies help break down complex tasks into smaller, more manageable steps, optimize processes, and even simulate potential scenarios. By specifying when and how to apply each planning method, the core ensures that multi-layered problems are effectively broken down into actionable components. This capability is essential for addressing queries that require extensive reasoning or the integration of multiple data sources.
Finally, contextual memory is an integral function of the core, rather than a separate module. This capability allows the agent to dynamically recall and integrate the most relevant information from previous interactions based on the current query. For example, if a user asks a follow-up question that builds on a prior conversation, the core can seamlessly incorporate relevant historical details to provide a coherent and informed response.
Technically, the core can also be configured with a specific persona, which imbues it with a unique style or character. This persona influences various aspects, such as tone, language, and even tool usage, ensuring that the agent’s outputs align with the user's expectations. For example, an agent focused on technical troubleshooting might adopt a formal, precise manner, whereas a personal assistant might use a more conversational, friendly tone.
In summary, the agent core is where the agent’s objectives, tool management, planning strategies, memory functions, and optional persona converge. It integrates these elements to interpret user inputs, formulate effective action plans, access necessary background information, and ultimately deliver coherent, context-aware responses.
What Is the Planning Module
The planning module enables an LLM-powered agent to address complex, multi-faceted problems by breaking the approach into manageable steps. This capability is especially important when the agent is tasked with solving highly intricate problems. To manage complexity, the planning module typically employs a combination of two key techniques:
- Task and Question Decomposition
- Reflection or Critic
When confronted with a complex problem, the agent needs to break it down into smaller, more manageable components. This process involves breaking down a broad or ambiguous query into specific, well-defined sub-questions or tasks.
For example, instead of directly answering the question, "What are the key insights from these financial reports?" the agent might break the task into several distinct steps:
- Extracting relevant figures from each report.
- Comparing performance trends across periods.
- Identifying the underlying drivers of revenue changes.
By decomposing the question in this way, the agent can address each component separately. This results in a more accurate overall response. This approach also increases the likelihood that the agent will select the most appropriate tool for each sub-task. After completing the initial breakdown and executing the sub-tasks, it is often beneficial for the agent to pause and evaluate its approach.
Reflection involves reviewing both the process and the outputs of previous steps to ensure they align with the original objective. Acting as an internal critic, this step allows the agent to identify any errors, inconsistencies, or opportunities for improvement. For instance, if the agent discovers that one of the sub-tasks produced ambiguous data, it might decide to re-run that particular analysis or adjust parameters to achieve a clearer result. This self-assessment not only improves the accuracy of the final answer but also helps the agent refine its future performance by learning from past experiences.
Together, these two techniques enhance the planning module, allowing it to transform any task, no matter how complex, into a sequence of smaller and manageable steps. By first decomposing the task and then reflecting critically on the process, the agent becomes better equipped to deliver precise, contextually rich answers, regardless of how complex the user's question may be.
What Are Tools
Tools are well-defined, executable workflows that agents can leverage to perform specific tasks. Similar to specialized third-party APIs or plugins, these tools extend an agent's capabilities beyond basic language generation. Instead of relying solely on the LLM’s built-in knowledge, agents can invoke these tools to access external data, perform computations, or interact with various services.
Tools can vary in complexity. An agent might use APIs that perform real-time searches over the internet, providing current news or data. It can also utilize more straightforward services, like a weather API, that returns current conditions. Even APIs for instant messaging or social media platforms can be integrated. This enables the agent to send messages, schedule posts, or interact with users on those platforms.
We can even use a code interpreter tool, allowing the agent to execute code snippets, solve complex programming challenges, or debug algorithms, which are tasks that would be difficult or error-prone if attempted solely through natural language generation.
In summary, tools are essential for bridging the gap between an AI agent's language-based reasoning and the practical execution of tasks. They empower the agent to act in the real world, ensuring that its responses and actions are not only coherent but also effective and timely.
What Are Memory Modules
Memory modules serve as repositories that store both internal reasoning logs and user interactions. This stored information is crucial for maintaining context, ensuring coherent responses, and enabling the agent to build on past interactions. There are two main types of memory modules:
- Short-term memory modules
- Long-term memory modules
Short-term memory functions as a ledger that records the sequence of actions, thoughts, and intermediate steps the agent takes while solving a task. Essentially, it captures the agent's "train of thought". This memory helps the agent keep track of its ongoing process, ensuring it doesn't lose context or repeat steps while working through a complex task.
In contrast, long-term memory logs interactions and events over longer periods of time. This memory allows the agent to recall previous conversations, understand recurring user preferences, and provide contextually enriched responses in future interactions. For example, if a user revisits a topic discussed earlier, the agent can reference past details to offer a more personalized and informed response.
To effectively retrieve information from both short-term and long-term memory, we must move beyond simple semantic similarity. Usually, a composite scoring system is employed, taking into account multiple factors:
- Semantic similarity
- Importance
- Recency
- Application-specific metrics
Semantic similarity defines how closely a stored memory aligns with the current question. For instance, imagine an AI agent that helped a user with travel planning. If the user later asks, "What were the best travel tips you mentioned for Europe?" the agent’s memory might contain a note from a previous conversation about "budget-friendly travel hacks for Europe." Although the phrasing differs, the semantic overlap between "best travel tips" and "budget-friendly travel hacks" helps the agent recognize that this stored memory is relevant.
Importance defines the significance of the memory within the context of the conversation. Consider a scenario where a user mentions a critical incident, like “My data was compromised last month.” This piece of information would be flagged as important due to its security implications. In future interactions, such as when the user asks “What steps should I take to secure my account?”, the agent prioritizes retrieving and referencing this high-importance memory to provide tailored advice.
Recency defines how recently the interaction occurred, with more recent memories typically holding greater relevance. For instance, if a user recently discussed "today’s market trends" in a conversation, that memory becomes particularly relevant for a follow-up query like, "Based on our latest discussion, what is the current market outlook?" In this case, the recency of the market trends discussion ensures the agent incorporates the most up-to-date context into its response.
Finally, in certain situations, there are specific metrics that hold particular relevance to the task at hand. For instance, in a healthcare context, an agent might store various pieces of patient data. In addition to the previously mentioned criteria, a composite score can be developed that takes into account domain-specific factors like "severity of symptoms" or "critical lab results." Then, when a doctor asks, "What are the most urgent issues to address for this patient?" the agent retrieves memories that rank highly based on these specialized metrics, such as an abnormal lab result flagged as critical, even if it isn’t the most recent entry.
What Are the Challenges in Building and Deploying AI Agents
Most of the challenges encountered when building AI agents stem from the inherent limitations of LLMs. By their nature, LLMs are prone to certain reliability issues. Despite advancements, even the most sophisticated models still "hallucinate" from time to time. This results in returning fabricated information that can be difficult to distinguish from factual data.
Additionally, because LLMs are nondeterministic, even minor changes in input can have a great impact on the answer received from an LLM. This unpredictability poses a major challenge, as ensuring reliability is one of the top priorities in the development of any automated system. We can implement "guardrails", which are rules that the agent must follow in all situations to mitigate these risks. However, such measures only reduce the problem rather than eliminate it entirely.
In addition to the previously mentioned challenges, agents also inherit any domain knowledge limitations present in the original LLM. Since the base LLMs used as the "brain" of these agents are typically trained to be versatile and perform well across a wide range of tasks, they lack the specialized expertise required for certain domains. This lack of domain-specific knowledge can hinder the agent’s ability to perform tasks accurately and effectively in specialized areas.
As mentioned before, we can mitigate this issue through fine-tuning and by making sure that our memory modules are properly configured. However, aside from training an LLM specifically on domain-specific data, there is no practical way to create an LLM that functions as a true specialist in a particular field. Unfortunately, this is an approach that requires vast amount of data and can be prohibitively expensive. This limitation makes it challenging to achieve deep expertise without significant investment in data and resources.
Finally, in addition to the typical challenges encountered when working with LLMs, agents, like any other autonomous system, are subject to a range of broader issues. These include security issues, scalability concerns, performance costs, and other complexities inherent in developing such systems.
These challenges make deploying AI agents more complex than they might initially appear, and it is far from a trivial task.
How to Build and Deploy AI Agents
Creating an AI agent is a particularly difficult task, however, it can be simplified by using frameworks specifically designed to streamline the process. Currently, there are numerous frameworks, both open-source and commercial, that ease development by offering pre-built implementations, tool integration, and other resources. These frameworks help bypass many of the problems encountered when building the entire system from scratch. This allows developers to focus on properly designing the system. Some of the popular frameworks include:
- LangChain and LangGraph
- Microsoft Autogen
- OpenAI Swarm
- Langflow
- AgentGPT
- Agno
- MetaGPT
Each of these frameworks brings its own strengths:
- Projects like AgentGPT and Agno provide robust features suitable for developing enterprise-level, integrated solutions.
- Projects like Langflow offer visual flow-builder UIs to lower the barrier for users who want to design workflows without deep coding knowledge.
- Newer projects such as MetaGPT represent a novel approach to multi-agent interactions, potentially shaping future developments in the field.
Ultimately, the choice of framework depends on the specific needs of your project.
AI agents represent a significant evolution in our approach to artificial intelligence, building upon the foundation of RAG systems to create more autonomous and versatile solutions. By combining a powerful LLM core with planning capabilities, specialized tools, and memory modules, these agents can break down complex problems, execute multi-step tasks, and maintain context throughout interactions. In our upcoming articles, we will explore how to leverage existing frameworks to design and deploy AI agents effectively.

