


Table of Contents
Applying machine learning to your organization can provide a huge competitive advantage. However, many businesses struggle to see returns after implementing a data science or machine learning project at their company. A 2020 MIT Sloan Management Review article called “Expanding AI’s Impact With Organizational Learning” described a survey of 100 companies done by the Massachusetts Institute of Technology and Boston Consulting Group. The survey revealed that only 20% of businesses saw significant financial gains after deploying machine learning. In order to successfully implement machine learning-based tools, enterprises need well-defined and standardized processes to effectively manage their data science projects. This guide will provide you with best practices for your projects so that you can make informed decisions for your organization when it comes to machine learning.
How to Structure a Data Science Project
Most data science projects have five phases:
1. Defining the Question
Like any scientific experiment, clearly defining a question to investigate is the key first step. Once you’ve established your initial question, you’ll continue to refine it as you conduct your research and analysis.
2. Conducting Exploratory Data Analysis (EDA)
Exploratory data analysis means evaluating your data to see if it’s suitable for answering the question you defined in the first phase of the project. Check if there’s enough data or if there are too many missing values. Consider if you need to collect more data. Once you’re done evaluating your data, use what you learned about the data available to you to develop a sketch of your solution. Note that there is no need for formal modeling at this stage.
3. Formal Modeling
Now you’re ready to build and run machine learning models. For this phase, you need to have a clear understanding of the question you’re asking and the parameters you want to estimate. During the formal modeling process, be sure to challenge your results from the EDA phase and revisit your initial assumptions.
- How to Set Up a Machine Learning Project as a Business Leader
- What Questions Can Machine Learning Help You Answer?
4. Interpreting Results
At this phase, you should have your final results from your model. Determine how they compare to your initial expectations before the analysis took place.
5. Communication
Communicating your results to your project stakeholders is the vital final phase of your data science project. Discuss with them your recommendations for the decision or action that should be taken next, based on your interpretation of your model results. Follow up to make sure that the value of the project is widely understood and that the resulting action items are done.
The foundation of data science is having clean, reliable and relevant data to mine for insight. Now that you know the rough structure of a data science project, let's dig a little deeper into the data collection and preparation phase.
How to Obtain and Prepare Your Data
Once you have a question to answer in mind, it’s time to gather the data you’ll use in your machine learning project. As the project leader, you should be heavily involved in the data collection process. The more involved you are, the better you can identify and prevent common mistakes.
The following is a list of eight common mistakes made in the data collection process:
1. Undefined Data Collection Goals
Make sure you have a well-defined goal in mind for the type of data you want before collecting it. Knowing what kind of data you’re collecting and why will make the data collection process much more efficient.
Without a well-defined goal, you risk gathering incomplete or incorrect data, creating what is also known in the industry as a “data swamp." Data swamps occur when companies collect data they eventually realize that they didn’t need. Data swamps are often formed because clear parameters on the types of data to collect weren’t set at the beginning of the collection period. To avoid a data swamp, prioritize cleaning and organizing data immediately after collecting it.
2. Definition Error
Definition error occurs when the question you’re trying to answer through your data science project is not defined, specific, or detailed enough. Setting clear parameters for data collection not only helps avoid a data swamp, but is also imperative for avoiding definition error as it can bring important distinctions for your question into discussion. Here are some example discussions to have with your team that may help reduce the possibility of definition error in your project:
- How does our company define a ‘customer’? For example, is a customer anyone who’s ever purchased a product, or only someone who’s spent over a certain dollar amount with our company?
- How much money did customers spend during the last quarter?
- Do you currently measure data by fiscal or calendar quarters?
- Do you have methods in your data to account for refunds, returns, and/or exchanges?
Article continues below
Want to learn more? Check out some of our courses:
3. Capture Error
Capture error usually occurs when two data items look or sound the same or similar—especially in the beginning—but are ultimately different, typically in terms of their meaning. Data items with similar initial sequences may be captured incorrectly if your data collection process doesn’t sufficiently distinguish between the two similar items.
Correctly capturing the data that you’re interested in is important for reducing the chance of capture error. Think about the best way to handle the data specific to your project and try to identify data collection methods that will minimize the risk for capture error.
4. Measurement Error
Measurement error is caused by the difference between a given value of a measured data point and its true value. Some examples of common measurement errors within data sets are:
- Data that is missing a certain filter that should have been applied (for example, forgetting to use a filter that removes outliers from your data).
- Data created using inconsistent reporting standards (for example, using different accounting standards across a data set for financial reporting).
- Data with calculation errors. Even simple calculation errors can greatly influence your results.
5. Coverage Error
Coverage error occurs when not all of the targeted respondents for a given data set are included in the data. For example, assume you want to collect data from the general population using an online survey. Because the elderly are typically underrepresented in online user demographics (in other words, not generally online as much as younger people), the data collected by an online survey would disproportionately represent those age groups that are more likely to use the internet.
6. Sampling Error
Similarly to coverage error, sampling error occurs when the sample of data selected for your project from a given data set does not appropriately represent the entire population of the data. A data science project must analyze data samples that accurately represent a target population if the goal is to effectively generalize the results in the end.
Here is one example of sampling error: Let’s say you ask your friend’s opinion about a product. It would be a sampling error to assume that the entire user population of that product has the same viewpoint as your friend. In this instance, the single data point of your friend’s opinion is not enough collected data by which to make generalizations about the opinions of users as a whole.
7. Inference Error
Inference error comes in two varieties: false negatives and false positives.
A false negative occurs when an incorrect prediction is made that assumes a certain attribute is missing. A false negative is failure to identify the signal that the model is searching for, when the signal is present. For example, a business might make a false negative inference error by initially discarding a new technology or tech product, assuming it is only a passing fad. Later, that company finds that adopting the new technology would have been beneficial and not doing so was actually a missed opportunity.
On the other hand, a false positive occurs when an incorrect prediction is made but this time assuming a certain attribute is present when it is not. A false positive is when the model thinks the signal is there, when the signal is, in fact, not present. Using the same example, a false positive is similar to wishful thinking. Although a company believes a product will help their business, they’ll realize a false positive inference error was made when the product in reality does not provide any benefits.
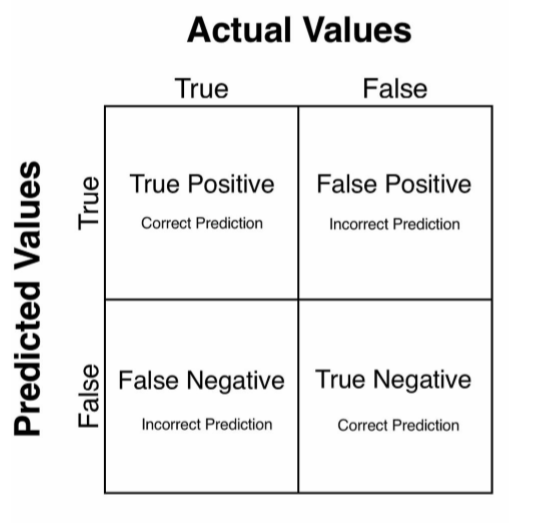
This matrix figure is a common visual representation of how inference errors relate to predicted versus actual values:
Image Source: Applied Artificial Intelligence, Mariya Yao, https://www.amazon.com/Applied-Artificial-Intelligence-Handbook-Business/dp/0998289027
Image: A model’s predictions, when compared to reality, will fall into one of the four matrix categories. Tally up instances of true positives, true negatives, false positives, and false negatives to understand and improve model performance in areas such as accuracy and recall. Machine learning packages like Python’s scikit-learn usually offer built-in functions to calculate model accuracy and recall rates.
8. Unknown Error
Unknown error originates from unseen situations or missing data. For example, online advertisements are often used to collect data on the interest of a potential customer through their interaction with an ad. However, sometimes users click on ads in an annoyed reaction to the ad popping up on their screen. In this context, the annoyance of the user is an unknown error that affects the data collected on ad clicks.
How to Build Machine Learning Models
After defining your question and obtaining and preparing your data, you’re ready to begin building a machine learning model. The following sections break down the process of building a model, as well as how to verify you’ve built a useful one.
Assess the Performance of Your Machine Learning Model
While working on your machine learning project, you may need to evaluate how successful your model is at producing helpful results. The following is a list of three metrics you can use as indicators of a successful model:
- Accuracy. Your model has a high percentage of classifications that were made correctly.
- Precision. Your model has a high percentage of true outcomes that were correctly identified out of all of the true classifications.
- Recall. Your model has a high percentage of true outcomes that were correctly classified as being true.
Trade-offs between precision and recall are common when analyzing the results from a model. Depending on the nature of your task, you may want to maximize precision and reduce recall, maximize recall and reduce precision, or balance the two.
For example, spam filters usually operate with an emphasis on precision to reduce error (a false positive would incorrectly send an important email to spam), while cancer screenings emphasize recall to reduce error (a false negative would fail to detect cancer in a patient, which could be devastating).
How to Avoid Common Mistakes with Machine Learning Models
There are two main types of issues that can come up with a trained machine learning model: underfitting and overfitting. Underfitting happens when a model is too simple and it does not capture all the complexities of your data. On the other hand, overfitting is when the model does not generalize well outside of your training data.
How to Organize Your ML Model's Workflow
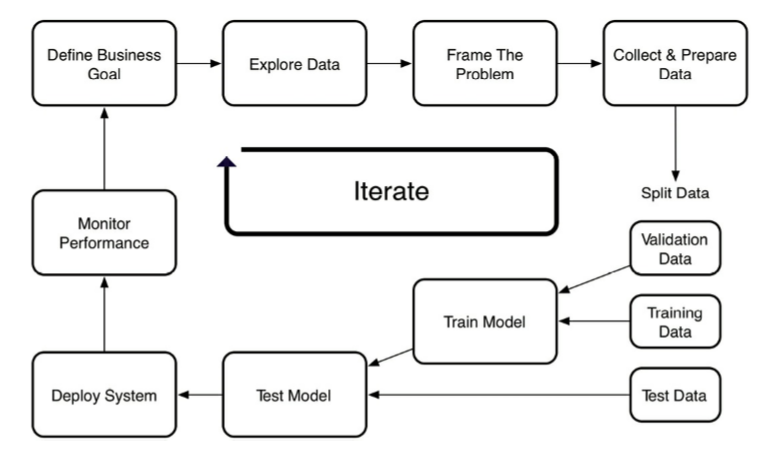
Let's take a look at supervised machine learning, which has a process that follows the steps summarized in the diagram below:
Source: Applied Artificial Intelligence, Mariya Yao, https://www.amazon.com/Applied-Artificial-Intelligence-Handbook-Business/dp/0998289027
- Define your business goal and avoid any vague requests (i.e., increase revenue).
- Examine existing data and processes.
- Frame the problem in ML terms. Your data science team is responsible for deciding how to prep the data, what technical approach to take, and what algorithms may give the best results.
- Centralize the data. This is a task for your data engineering team.
- Clean the data.
- Split data into two distinct sets. Firstly, the training data which is used to train the model, and then the test data to estimate the model’s performance on new and unseen data.
- Train several different models using your training data. Pick the one that performs best for your use case.
- Validate and test the model. You need to repeat the training and testing phases until you find the best model for your goal.
- Deploy model.
- Monitor performance.
- Iterate.
Let’s look closer at some things that you may come across during your ML workflow.
Experiment and iterate
Experimentation and iteration are important phases of your machine learning workflow.
Coding your machine learning system is only the beginning and you need to develop and maintain the infrastructure of the code. Tech debt represent the downstream work needed to fix hacky and rushed initial builds. There are three types of ML debt:
- Code Debt - to solve code debt, you need to revisit and fix old code that may no longer serve your project.
- Data Debt - throughout your project’s lifetime, you may find that the data initially used to train the algorithm is no longer correct or relevant.
- Math Debt - it often comes from the complexity of the model’s algorithms.
Deployment and Scaling
Machine learning operations, or MLOps for short, is the discipline that handles the deployment, monitoring and management of machine learning models in production. Companies that do machine learning at scale usually have their own development and deployment environment.
However, if you are just starting out, there are also off-the-shelf alternatives available to homegrown platforms that you may want to try: MLflow, TensorBoard, Algorithmia, and most of the MLaaS platforms that you can learn more about here:
Iteration and Improvement
You need to retrain your ML models as new data comes up and external factors change. The frequency of your updates depends on: the algorithm, the situations, and the data availability. A good rule of thumb is to spend half the time on measurements and maintenance that you spend on model creation.
How to Interpret and Communicate of Results of Your ML Project
Now that you understand what an ML project looks like and what are some of the challenges you may encounter, let’s go to the final stages and see how you may want to interpret and communicate your results.
You may want to get the word out there through some of the following formats:
- Internal Reports or Presentations. Communicate to everyone in your organization about this project, what it does and how it can be used. You can use learning lunches, reports, presentations, or a bigger launch event to tell them about it.
- Interactive Web Pages and Apps. If you have a heavy analysis, this is a good way to visualize your results.
What Are Best Practices for Machine Learning Engineering?
"To make great products, do machine learning like the great engineer you are, not like the great machine learning expert you aren’t." - Martin Zinkevich, Research Scientist at Google
Rule 1. Don’t Be Scared to Launch a Product Without ML
First of all, focus on solving one problem at a time, and build a solid data pipeline and generate data through heuristics. Sometimes, ML may not be a necessity for your product, so don’t use it until you have all the needed data.
Rule 2. Design and Implement Metrics
This is the first step you need to take before formalizing what your ML system will do. Track as much as possible in your current system.
Rule 3. Choose ML Over a Complicated Heuristic
Although a simple trial and error is appropriate when launching your product, a complex heuristic is unmaintainable.
This overview provides a common framework that you can refer to when you approach any data science project. Whether you build machine learning models yourself, or you collaborate with people who do, this guide has hopefully given you a good perspective of the project workflow and possible drawbacks.

