



For years, the dominant paradigm in the landscape of Large Language Models (LLMs) was autoregressive generation. In this approach, Modern LLMs generate sentences word by word, much like we might type them out. This sequential method has been the standard across virtually all LLMs, and it has worked remarkably well.
Indeed, over the past few years, the field of AI has seen one breakthrough after another, much of it driven by this very technique. But now, a different methodology is starting to gain traction. What if we could generate answers all at once, instead of word by word?
This new approach means stepping away from the standard autoregressive architectures that power most LLMs. It adopts a different kind of architecture that is not yet common in the field of Natural Language Processing (NLP). However, this architecture has proven to be highly effective at generating large amounts of data all at once. The type of model we are talking about here is called a diffusion model.
Just as autoregressive architectures dominate the field of NLP, diffusion models dominate generative AI in the field of Computer Vision (CV). Nearly all of the most popular AI models for generating art are based on some variant of a diffusion model. In this article, we will explain how diffusion models work on a conceptual level. We will also explore how these models can be adapted for use in NLP.
How Do Standard Diffusion Models Work
Diffusion models are a type of generative AI that learn to create new data by understanding how to systematically destroy and then reconstruct information. The easiest way to explain the concept is by looking at how diffusion models are used in the field of Computer Vision.
Imagine taking a clear image and gradually adding small amounts of random noise to it, step by step. Eventually, the original picture becomes completely obscured and looks like static. This process is called forward diffusion.
After turning the image into pure static, the model tries to reverse the process. This step is called reverse diffusion and is at the core of all diffusion models. The model learns to reconstruct a clean, coherent image that resembles the original training examples. Through this process, it also learns to generate entirely new images starting from random noise.
Reverse diffusion is of utmost importance. In the context of diffusion models, performing inference with a trained model is equivalent to performing reverse diffusion. To generate something new, the model starts with pure random noise. Then, through multiple iterations, it gradually removes the noise until a high-quality image emerges at the end.
Usually, when using diffusion models, we don’t want the model to replicate data already in the dataset. Instead, we want it to generate completely new and unique outputs. To achieve this, we provide the model with prompts that condition it to generate something not present in the training data. These prompts are encoded and injected into the model’s denoising steps. This guides the model in deciding what kind of image to generate.
This influences the model's generation process. During forward diffusion, the model adds random noise to images. Because of this, when it learns to denoise an image, it doesn’t just memorize one correct answer. Instead, it learns a distribution of likely outcomes. Let’s break this down to make it clearer.
AI models can’t see images. They can only work with numbers. For them, an image is a large matrix where each pixel is represented by a particular value. Therefore, when we add random noise during forward diffusion, we randomly corrupt these pixel values. As a result, during reverse diffusion, the model does not predict the exact pixel value. Instead, it predicts a range of potential pixel values. Prompts enable us to steer the model towards a particular value within that range. This guides the model to generate an image that matches the description in the prompt.
So, if we can condition a model to generate a particular pixel value using a prompt, could we also condition a model to generate a particular word based on the prompt we provide? After all, models can’t read words. They see words as numbers, just like they see pixels. This is the basic idea behind Language Diffusion Models (LDMs).
Article continues below
Want to learn more? Check out some of our courses:
How Do Language Diffusion Models Work
The training process of Language Diffusion Models also includes forward diffusion and reverse diffusion. However, instead of starting with a real image, we start with a real sentence. During forward diffusion, noise is gradually added to the sentence across several steps. This noise can be added to embeddings or discrete tokens until the sentence becomes unrecognizable. At this point, we have the textual equivalent of static.
During reverse diffusion, a neural network learns to reverse this process. It transforms the random static back into coherent, human-like text step by step. Once again, inference means performing reverse diffusion guided by prompts. The model receives a prompt embedding to guide the denoising process. This helps produce the result we are interested in.
Unlike a standard autoregressive language model, a diffusion language model does not generate an answer word by word. Instead, it starts with a sequence of random placeholder tokens. The model then iteratively refines the entire sequence through multiple steps. With each step, the sequence becomes more coherent and meaningful. By the end of this process, we have a fully sensible answer.
This iterative refinement allows the model to consider the global context of the text as it generates it. In comparison, an autoregressive model is limited to the initial prompt and the tokens it has already generated in the current sequence.
In layman’s terms, an autoregressive model uses the initial prompt to generate the answer word by word. When generating the second word, it relies only on the prompt and the first word as context. In contrast, diffusion models start with a very blurry or jumbled-up version of the entire answer. Based on the prompt, they reveal the complete answer through a series of iterative steps. Because the model processes the entire answer at once, it can ensure that all parts fit together well.
What Are the Advantages Of Language Diffusion Models
The main advantages of Language Diffusion models are:
- Parallel generation
- Bidirectional context modeling
- Controllability
- Diversity
- Less memorization
Diffusion models generate the entire output, or at least large chunks of it, all at once. This parallelization leads to significantly faster generation compared to standard autoregressive models. However, because the model goes through multiple denoising steps, it may be slower when generating short sequences. Conversely, for larger outputs, diffusion models are much faster than autoregressive models.
Additionally, diffusion models perform much better on tasks like text infilling, editing, and generating text with specific structural constraints. This is the result of considering the entire sequence during each denoising step.
By their very nature, these models are also well-suited for controllable generation. It is easier to steer them toward specific styles, lengths, or content requirements.
Furthermore, the outputs of diffusion models exhibit much greater diversity. By sampling different initial noise vectors, these models can naturally generate varied results. This reduces the need for complex sampling strategies like beam search.
Finally, research suggests that diffusion models memorize less than autoregressive models. This leads to more novel and consistent samples generated from scratch.
What Are the Disadvantages Of Language Diffusion Models
While diffusion models offer clear advantages, they also come with certain disadvantages in language generation:
- Computational cost
- Training complexity
- Performance on reasoning tasks
- Infrastructure limitations
Running diffusion models can be computationally expensive. Each denoising step often requires a full pass through the model. Some studies suggest that, for comparable accuracy, diffusion models may have higher inference costs than autoregressive models.
Training these models is often more complex than training autoregressive models. There are many sensitive hyperparameters to tune during the training process, such as noise schedules, loss weighting, and regularization strategies. This does not mean training autoregressive models is easy, but diffusion models involve additional factors that require careful consideration.
Current language diffusion models fall behind large autoregressive models on complex reasoning tasks that require sequential logical thinking. This does not mean they are bad at reasoning. However, they cannot yet match the performance of autoregressive models, which are well-suited for such tasks due to their sequential nature.
Finally, existing machine learning infrastructure is heavily optimized for autoregressive models, as they are the most widely used. This makes deploying diffusion models into production more challenging.
How Well Do Language Diffusion Models Perform
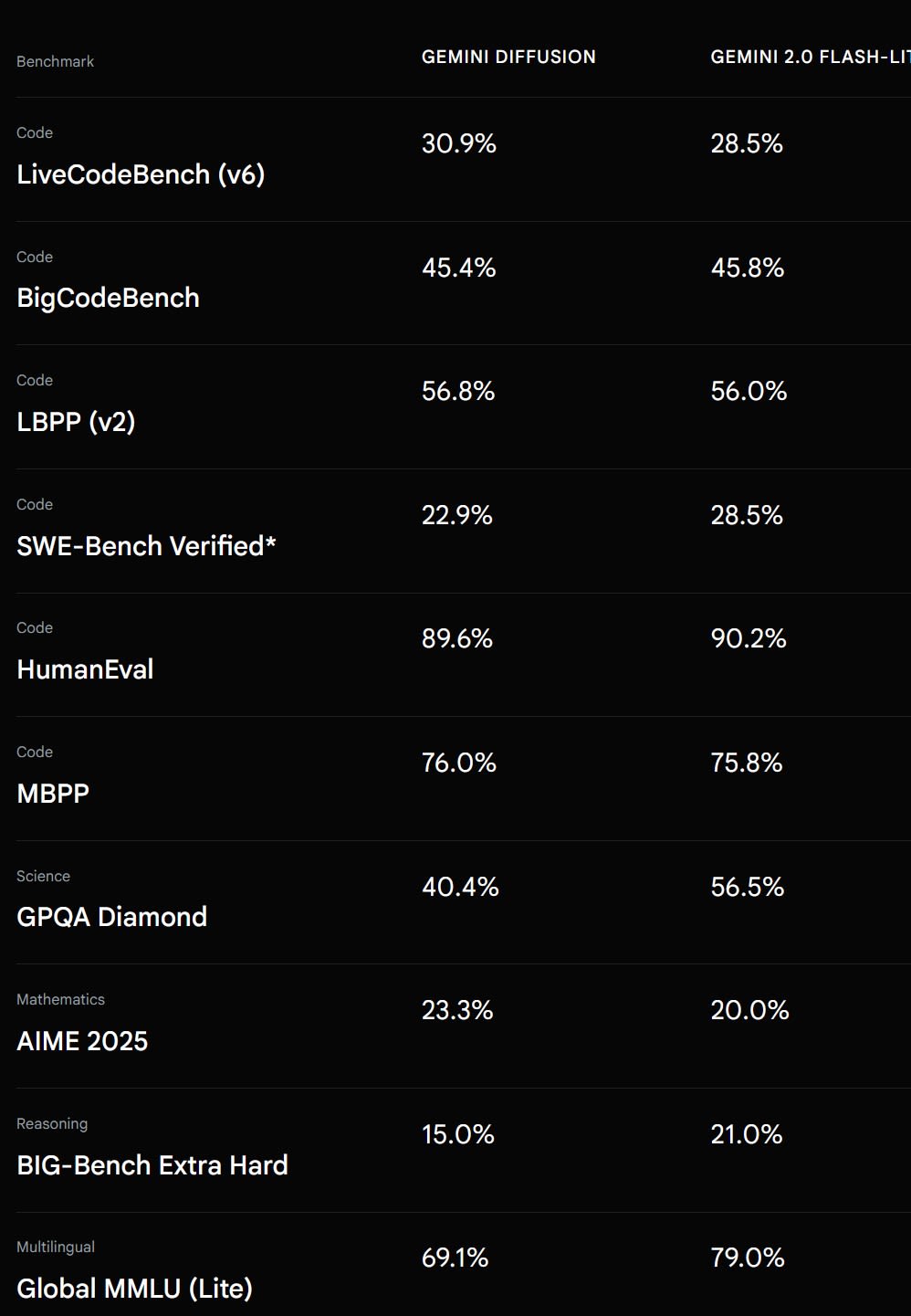
Currently, only Google is actively developing an advanced Language Diffusion model. This variant is called Gemini Diffusion and can be accessed online by joining a waitlist. In terms of performance, Gemini Diffusion is nearly equivalent to Gemini 2.0 Flash–Lite, but runs five times faster.
Gemini 2.0 Flash–Lite is not the best model available today in the field of LLMs. However, its performance is still strong compared to earlier versions, before newer releases like Gemini 2.5 appeared.
Let’s compare the performance of the two models on some common benchmarks:
Gemini Diffusion isn’t the first Language Diffusion model ever released, nor is it the only one. However, it is by far the best model currently available. That said, Google still considers it an experimental model. As a result, we will have to wait some time before it becomes widely available on Google’s platform.
In this article, we explained how an approach commonly used in Computer Vision can be adapted to text data. While autoregressive models have long set the standard for language generation, their sequential nature creates bottlenecks in speed and limits their ability to understand global context.
Diffusion models, inspired by their success with continuous data, offer a compelling alternative. They enable parallel generation and leverage bidirectional context, which is particularly beneficial for certain tasks. Although diffusion models do not yet match the performance of autoregressive models, their unique advantages make further development in this area worthwhile.

