
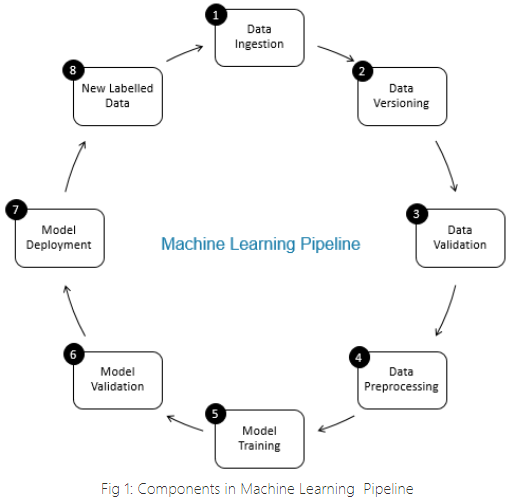


Table of Contents
- How to Define the Problem Your Data Model Will Solve
- What is Exploratory Data Analysis (EDA)?
- How to Create The Development Sample for Your Data Model
- How to Prepare the Data for Your Model
- How to Build Your Data Model
- Case Study: Bank Roboadvisor for Customer Service Calls
- Final Thoughts on External Venders for Building Predictive Data Models
Although your organization may always hope for a successful data science project, the unfortunate reality is that plenty of projects fail. That happens because the data science process needs to have a very clear and well-organized plan.
In this post, I break down a roadmap comprising eight steps for a successful data science process.
How to Define the Problem Your Data Model Will Solve
The goal when you are trying to define a problem is two-fold. First of all, you need to understand the precise needs of your business. Secondly, you need to find a way to express that numerically so that the model can understand it.
For instance, if you are the sales director of a retail store, you may have the goal of building a predictive model that identifies your best customers. Once you have this goal in mind, you have to clarify what you mean by "best" - does "best" mean the customers that bring your business the highest financial income? How do you measure the economic contribution of your customers? Is that by gross sales or net profit?
Ask further clarifying questions like: are you referring to your customers’ contribution per store visit, per click, or maybe per unit of time? Go in-depth and define what you mean by "customer" - the individual or the household contribution? These are all examples of good questions that could help you identify and clarify your problem.
What is Exploratory Data Analysis (EDA)?
EDA can help you find out what databases your organization has and the purpose of each database. During this step, you need to explore the content of your databases and eventually create a dictionary of data items and the type of format they have. Other things that you need to know about your database include: how often is it updated and maintained and whether or not it’s updated in real-time or batch updated.
Also, consider what data you are currently using to make data-driven decisions - this type of data could be valuable for your ML process. Decide what part of the data you already have that can be used to answer your defined problem, and look out for any apparent relationships within that data. Moreover, go a step back and look at your problem again to know what data to use - is that a classification or regression problem?
Next, during this analysis, focus your attention on potential questions about the machine learning system you need to build. Think about what other decision-making systems already exist in your organization. Can you implement the new model within the existing system, or do you need to create something entirely new
How to Create The Development Sample for Your Data Model
The previous step focused on the existing data that you have. In this step, you’ll need to look even more closely at this data.
- Documentation (Meta-Data) - how complete is the data dictionary you created during the EDA? Data rarely exists in only one place, so it’s your job to find it.
- Dead Data - don’t use data that you no longer understand in your models.
- Potential New Data Sources - explore new data sources that are either internal or external. You could collect data from censuses or even from social media.
What Data Should You Exclude?
Inexplicable Data
Also called dead data, as highlighted above, it’s essential that you don’t build models with data that you don’t understand. Pay attention to this, especially if your models are deemed strategically important or subject to regulation.
Out-of-Date Data
This is data that is no longer relevant to you or your business. For example, it would be pointless to use data about the relationship between people and cell phones before smartphones came into play.
Data That Doesn't Represent Your Target Audience
Assume that you are developing a revenue model for your online customers - use your common sense and don’t include in-store transactions.
Unstable Data
Check if the data used in the ML process will be available during model deployment. When you undergo model implementation, exclude this kind of unstable data.
Legally and Ethically Wrong Data
It’s not appropriate to use personal data concerning race, gender, and sexual orientation.
Article continues below
Want to learn more? Check out some of our courses:
Deterministic Cases
For instance, if you decide that a group of customers will receive a discount no matter what, exclude their data from the development sample.
How Much Data Should You Include In Your Data Model Development?
The amount of data you should include in your data model all depends on the problem you’ve defined during the first step, and on the type of algorithm you plan to use. For instance, if you use neural-networks or deep learning algorithms, those require as much data as possible. However, for most business problems, sampling more than a few thousand cases provides little benefit.
How to Prepare the Data for Your Model
Image Source: 'Data Validation in Machine Learning is imperative, not optional', Aditya Agarwal (2021)
How to Pre-Process Your Data for Your Model
Calculate the Fields of Your Data
For instance, age is more predictive than birth date, so age may need to be calculated.
Clean Your Data
Remove and reformat missing or incorrect data.
Consolidate Your Data
This means that you need to represent all the similar data in a similar way. For example, there may be a data item with values represented differently, although they essentially mean the same thing. You’ll need to consolidate all these values using a single one.
Convert Your Data to a Numeric Format
Textual data needs to be converted to dummy variables (i.e., 0 and 1) because ML algorithms best understand numbers.
Standardize Your Data
Scale data so that everything has similar values. For example, in object recognition, pixel intensity is standardized to the average pixel intensity across all the existing images so that different lighting won’t be an issue.
What is Feature Selection?
During data preparation, you’ll also need to select the variables you want to use in the ML training phase and which variables you don’t want to keep anymore. Conduct statistical tests to find out how well each feature is correlated to the predicted outcome. Keep only the features that have a clear correlation with the result. Here, you’ll probably end up with only 1-10% of your initial data items.
How to Build Your Data Model
This is the part you are probably most excited about, and the truth is that you should be because it’s the "sexiest" part of the whole process. The ML software is highly automated, so you don’t need to be an expert to build a model, but you do require technical experience to pre-process the data, interpret your results, and take action based on these results.
When you are done building your model, it may look highly accurate just because ML functions on rules and logic. However, sometimes, you'll see that your model is useless when you take a closer look.
For instance, if you build a model that determines which financial borrowers to loan to, you may find at the end that the model predicts a mortgage with 97% accuracy - this sounds good, doesn’t it? But what if 98% of borrowers pay their mortgage on time and only 2% default? If you predict that all the mortgages will be repaid, you would only be wrong 2% of the time - not 3% of the time like the model.
How to Assess Your Data Model’s Performance and Validate the Results.
There are three main types of validation that you’ll need to consider at this point:
- Quantitative Validation - you’ll have to use test data (i.e., never seen data) to run your model.
- Qualitative Validation - check all your results and the overall model against legal and ethical restrictions. Make sure all the data sources are available in production.
- Business validation - assess your model from the point of your business: lookout for key performance indicators and bottom-line benefits.
How to Build a Decision Logic System Based on Your Model
For a decision logic system, it’s good that, from the very beginning, you choose an active machine learning system rather than a passive one, because the active models decrease the possibility of human decision override. Explore how you’ll use your model and whether that’s going to happen within your existing workflow, or if you have to create a new workflow.
What is Model Deployment and Monitoring Infrastructure?
During model deployment, you need to ask yourself if you have the necessary data engineering talent to deploy and monitor the system. Then, decide on the metrics you will use to ensure the proper functionality of your system. Also, consider when it may be time to redevelop and tweak the system.
Case Study: Bank Roboadvisor for Customer Service Calls
A credit card provider developed a roboadvisor to increase efficiency and productivity within their call centers. The development sample consisted of thousands of recorded customer service calls, and it was pre-processed to separate specific words, phrases, and sentences associated with each of the following call types:
- Calls of customers asking for their account balance
- Calls of customers who wanted a list of their recent transactions
- Calls of customers that reported a lost or stolen card
- Calls of customers that asked for their account to be closed
- Other customer issues
The Data Model Setup
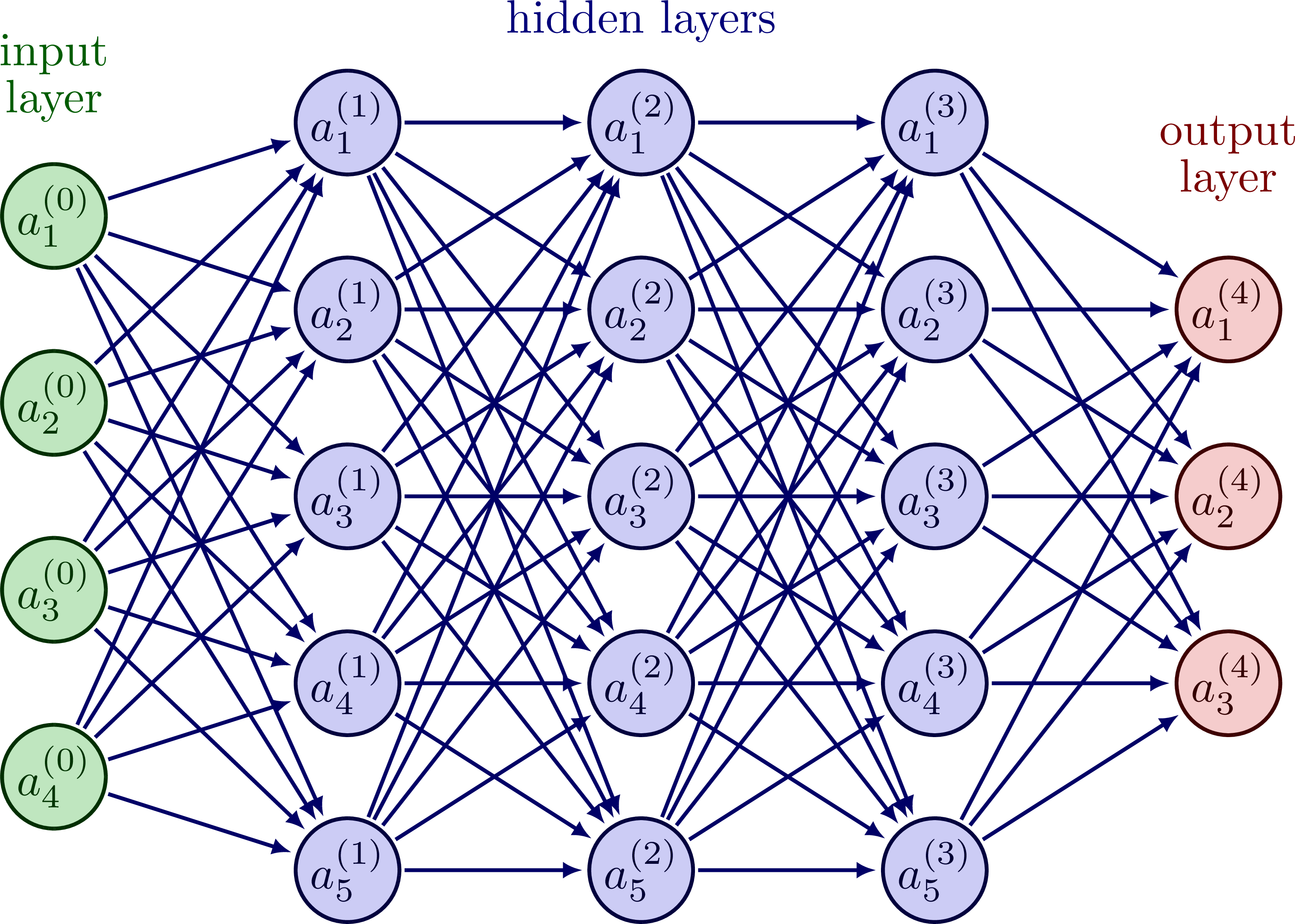
To create the roboadvisor, the credit card provider used a deep neural network predictive model. The model used the flags pre-processed to categorize calls and then perform an action based on the call category.
The first four call types make up 60% of all the possible calls, so it was simple to find standard responses and automate them. When the customers were not happy with the automated response, they were passed on to an actual person. The fifth type of call was always sent to an actual person.
Image Source: Neural Network, https://tikz.net/neural_networks/
Business Validation of the Data for the Model
Before the deployment stage of the roboadvisor, the manager had to calculate the savings in time & money from automating this process. On the other hand, they also considered maintaining the staff to see if the service levels improved.
Additionally, they needed to examine the number of possible times that the customers won’t get a correct answer from the roboadvisor. Based on this, the roboadvisor could be tweaked to decrease the staff levels while the service levels are improved.
Formulating Decision Rules for the Data Model
If the goal of the roboadvisor is to decrease costs and increase profit, then a cost/ benefit analysis needs to be done. For this, the credit card provider needed to know: the average duration of calls, the cost of a usual call, the proportion of calls that can be automated, the costs of the roboadvisor, and the time taken to deliver the predictive model.
Final Thoughts on External Venders for Building Predictive Data Models
Many external vendors can overhype and say that a predictive model can be ready in a matter of minutes. However, this can happen only if your data is already clean, formatted, and available in one place - which is rarely the case. If you don’t care too much about how the predictions are made, delivered, and in what format, or if you don’t have to comply with legal and business requirements, then you may as well believe the vendors - but again, there are little chances that this is the case.
What I have presented here is a roadmap including all the steps of a successful data science process. You can use this as a guideline and use your favorite tools to do this. However, remember that a well-defined and clear plan can beat any fancy tool out there.

