


For most of software's history, the specification was the thing you wrote before the real work began. It acted as the preamble for the code that was to be written. Nowadays, as AI agents are taking over most of the work in terms of implementation, properly defining a specification is more important than ever. In fact, one could even argue that it is becoming the most important artifact that a software team produces. Write a vague spec, and the agent you are using will produce sub-par quality software. Write a precise one and the agent can build, test and iterate with remarkable autonomy. This shift in thinking, termed spec-driven development, is quickly becoming the dominant approach among teams building seriously with AI coding agents
In this article, we are going to look at what spec-driven development is and why it is becoming the standard way to build software with AI coding agents in 2026. We will also explore the specific problems it solves, the challenges it does not address, and how it is changing the role humans play in software development.
Deep Agents, Part 1: What They Are and How They Work
What Is Spec-Driven Development
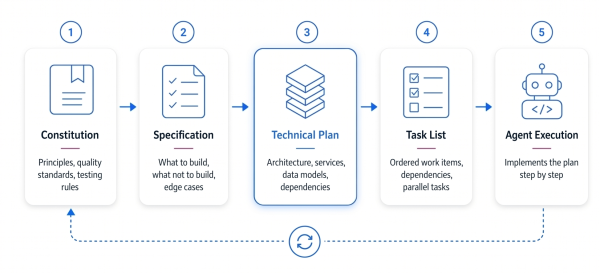
The core idea of spec-driven development is simple. Before any code is written, a team needs to produce a structured chain of artifacts. The artifacts that we need to create are:
- constitution
- specification
- technical plan
- task list
The first artifact is the constitution. It captures the durable, non-negotiable principles of the project, defining the quality standards, testing approach, architectural constraints, and decision rules. It is the document that tells the agent how the team builds, and it applies to every piece of work that follows. Basically, it is the document that prevents the agent from making sensible, but wrong decisions, such as choosing a framework you don't use, omitting tests because none were specified, structuring code in ways that will be painful to maintain. Stable stack choices may belong there, but feature-specific architectural and dependency decisions usually belong in the technical plan. A well-written constitution is a standing instruction to every agent that touches the codebase, present and future.
The second artifact is the specification. It describes what needs to be built and why, covering what the system should do, what it should not do, and how it should behave in edge cases. This is where vague ideas get turned into precise requirements. Be very careful here to avoid any level of ambiguity. "Users should be able to sign in" is not a specification. "Users authenticate via email and password; failed attempts after five tries lock the account for fifteen minutes; sessions expire after seven days of inactivity" is. You should strive to define everything in as much detail as possible.
The third is the technical plan. It takes the specification and translates it into architecture, telling the agent which services, which data models, which external dependencies, and which patterns should be used to deliver what the specification requires. This is where the main engineering decisions get made. The agent will handle the implementation as long as you properly define the design choices it needs to execute.
Finally, we have the task list. At its core, it is our plan broken down into an ordered, executable list of work items with dependencies made explicit. Independent tasks are marked for parallel execution. This task list acts as a clear roadmap the agent can follow without needing further guidance on what to do next.
Each artifact builds on the last, and each one is checked for consistency with those before it. A spec that contradicts the constitution gets flagged. A plan that introduces undocumented dependencies gets surfaced. A task list that misses a requirement gets caught before a single line of code is generated. The point of creating this chain is to make it extremely straightforward for AI agents to understand what we want them to build, and how they should do it. Where this differs from traditional requirements documentation is that traditional documentation is written under the assumption that it will be read by humans, meaning that some level of ambiguity is tolerated. There is zero tolerance for ambiguity when it comes to writing specifications for agents. They can't fill in the gaps using their own judgement effectively, at least not yet.
For instance, if you ask an agent to do something, such as build a user authentication system, it will do that, but the system it builds might be completely different from how you originally envisioned it. It might use OAuth because that seemed modern, or a username and password form because that seemed simple. It might send a verification email on signup, or it might not. It might lock accounts after failed login attempts, or allow unlimited retries. It might store sessions in a cookie, in local storage, or in a database. It might set sessions to expire after an hour, a day, or never. Every one of those is a legitimate engineering choice, and the agent will make all of them without asking.
A useful specification would make sure that the agent doesn't need to "guess" how you wanted the system to look like. It would strictly define that users authenticate via email and password, and that verification emails are sent on signup and must be confirmed before login is allowed. It would tell the agent that password resets are handled via a time-limited link sent to the registered email address, valid for thirty minutes. It would also tell the agent that failed login attempts lock the account after five tries for fifteen minutes. It would also define that sessions are stored server-side and expire after seven days of inactivity. The aforementioned is just part of what a detailed specification might look like in practice. That level of detail might seem excessive, but it is the minimum required to get the agent to create the system you actually want.
Deep Agents, Part 2: Building a Local Code Debugger with Gemma 4 E4B
Article continues below
Want to learn more? Check out some of our courses:
Why Is Spec-Driven Development Becoming The Standard
While spec-driven development has been advocated for decades, it was often not worth it to write such thorough specifications, as it took longer than many teams felt they could afford, and the benefits were often invisible until something went badly wrong late in delivery. Essentially, many teams defaulted to the approach of "we'll figure it out as we go." AI coding agents are what finally made spec-driven development worth the effort, for two reasons.
First, agents can now handle large portions of implementation reliably when given clear instructions. For teams delegating larger tasks to agents, the bottleneck is increasingly shifting upstream. Gone are the days where the limiting factor is how quickly a team can produce code. Nowadays, the true bottleneck is how fast a team can produce high-quality specifications that allow agents to churn out the correct code at rates humans could only dream of.
Second, the cost of a bad specification is now far higher and far faster to manifest. An agent working at speed on a vague spec produces huge quantities of software that can take a team weeks to debug. Basically, a vague spec no longer just slows you down, but because of the rate at which agents can produce code it scales your mistakes.
Noticing this newly emerging trend, the tooling ecosystem has responded accordingly, with GitHub announcing Spec Kit in September 2025 as the clearest example. Spec Kit is an end-to-end framework built entirely around the spec-first workflow, complete with slash commands that walk teams through constitution, specification, plan, and task generation before any implementation begins. Even leading coding-agent tools are following suit. Cursor, Claude Code, GitHub Copilot, OpenAI Codex and others have all started increasingly supporting planning-first workflows that separate analysis from implementation. All of this demonstrates that the entire industry has shifted towards a very simple paradigm, urging developers to understand and specify before they start building.
What Is The Role Of Software Engineers In Spec-Driven Development
While at first it might look like as though spec-driven development is going to cause engineers to lose their jobs this couldn't be further from the truth. Actually, it is the opposite. Spec-driven development makes engineering judgment more visible, not less. The decisions that shape a system are now captured explicitly in artifacts rather than embedded implicitly in the code. While someone with no software engineering experience might believe that decisions such as what a system should do, how it should be structured and what constraints it must respect are easy, that couldn't be further from the truth and is actually where the bulk of software engineering knowledge lies.
The only thing that spec-driven development is going to change is where engineers spend their time. Instead of spending time writing boilerplate code, they will be writing constitutions that capture hard-won architectural lessons. Instead of implementing features line by line, they will spend time reviewing whether the agent's output actually matches the spec's intent. Essentially, the whole approach to software engineering will change from fixing problems to trying to avoid them in the first place. After all, why spend time debugging problems if they could have been prevented by creating a more detailed specification.
LangGraph Swarms, Part 1: What They Are and How They Work
What Spec-Driven Development Does Not Solve
Even when working with extremely detailed specifications agents will still make mistakes that an experienced software engineer will need to handle. Better specifications will not suddenly make AI coding deterministic or remove the need for human judgement. Agents can misinterpret even the best written requirements, producing code that technically satisfies the spec while introducing subtle architectural problems. They can even generate implementations that pass all tests but accumulate long-term maintainability debt.
This is why verification remains as important as specification. The spec-first workflow is most valuable when it is paired with tests, CI gates, scoped permissions, and genuine human review. When OpenAI declared in February of 2026 that their agents created a million-line application with zero manually-written code they conveniently shifted the focus from the fact that human engineers were still involved in the process, doing constant review, steering, and harness refinement. They might have written zero lines of code, but they steered the entire process.
This leads to the final conclusion that the teams that will get the most from AI-native development are not necessarily the ones with access to the best models. They are the ones that can make their intent easy to understand for AI agents. Better specifications, more explicit constitutions, clearer plans, better defined constraints and all of the other artifacts we talked about in this article, if treated as first-class engineering outputs rather than administrative overhead, are what is going to differentiate which teams ship high-quality code fast, and which just produce a lot of code in a short period of time. In 2026, the spec is becoming the control surface for AI-native software engineering, not because code no longer matters, but because agents need explicit intent, constraints, plans, tests, and review criteria before they can produce reliable software at speed. The teams that figure that out earliest will have a noticeable advantage that no model upgrade can replicate.

![[Future of Work Ep. 2 P2] Future of Learning and Development with Dan Mackey: Automation, ROI and Adaptive Learning](https://res.cloudinary.com/edlitera/image/upload/ar_16:9,c_fill,f_auto,q_auto,w_100/trgtawmebf1mylb4mfb55vazc0li?_a=BACJ3SGT)