






Table of Contents
There are two key issues that must be addressed when creating a high-quality Natural Language Processing model:
- How to represent words in a format that can be understood by computers that only process numerical data.
- How to transform human language into a set of attributes that a computer can analyze.
You can solve the first problem of word representation with word embeddings. The embeddings create a numerical representation of words that computers can process. To tackle the second issue, you need an advanced Deep Learning model, like a Transformer model, to model a sentence as a sequence of words.
- What is the Importance of Word Embeddings?
- Intro to Transformers: The Encoder Block
- Intro to Transformers: The Decoder Block
While I have previously covered what word embeddings and the Transformer architecture are, I have not yet told you how to create word embeddings in Python. One of the most straightforward and popular methods for creating word embeddings is to use the Gensim library. In this article, I will teach you how to create word embeddings with Gensim. In a future article I will expand on this topic by showing you how to use pre-trained embeddings.
What is Gensim?
Gensim is a Python library designed to process raw data efficiently using unsupervised Machine Learning algorithms. It supports various corpus formats such as plain text files, JSON, and different database systems. It is very popular because it uses established algorithms that have been extensively tested and evaluated for their effectiveness in various Natural Language Processing (NLP) applications and it offers memory independence.
- How to Use Machine Learning to Automate Tasks
- Self-Attention in Natural Language Processing: The Complete Guide
In my opinion, Gensim is a safer choice for any organization using Machine Learning for the very first time because it uses demonstrably reliable algorithms. Unlike other libraries that use the latest algorithms even if they haven't been sufficiently tested, Gensim uses extensively tested algorithms, used by prominent organizations. It’s tempting to employ state-of-the-art algorithms that offer the advantage of surpassing outdated algorithms, but, in many cases, the latest algorithms are not actually better than their predecessors. It is generally wiser to use optimized versions of older algorithms for practical purposes rather than rely on unproven, new algorithms that may require months, or years, of optimization.
- How to Summarize Text Using Machine Learning Models
- What Are the Most Popular Machine Learning Service Tools in 2023?
Gensim achieves memory independence through a technique known as "streaming" or "lazy evaluation." This means Gensim processes the information in smaller portions rather than simultaneously loading the complete data set into memory. This approach enables Gensim to handle extensive amounts of text without substantial RAM usage, making it an effective solution for managing large-scale NLP projects.
What Can Gensim Do?
As a library specifically designed for NLP and unsupervised topic modeling, Gensim can perform a plethora of tasks, including:
- Topic modeling
- Document similarity evaluation
- Text summarization
- Word embedding creation and manipulation
- Corpus transformation
- Text preprocessing
- Document classification and clustering
Out of this list, Gensim is most commonly used for creating and manipulating word embeddings. You can, of course, use it for one of the other tasks, but in general, there are better options than Gensim if you want to perform a task such as text summarization.
Article continues below
Want to learn more? Check out some of our courses:
How Do You Create Word Embeddings Using Gensim?
Gensim provides multiple popular algorithms for creating word embeddings, but the two most popular are Word2Vec and FastText. You can also use other algorithms or pre-trained embeddings, but that is something I will cover in future articles. For now, I will focus on the two most popular algorithms.
Tomas Mikolov and his team at Google developed the Word2Vec algorithm. It uses a neural network to create word embeddings and is one of the most popular algorithms for creating word embeddings. The FastText algorithm, on the other hand, was created by Facebook's AI Research lab. It is an extension of the Word2Vec model and functions very similarly to Word2Vec.
There is no one-size-fits-all answer to which algorithm is the best, as the performance of different algorithms can vary depending on the specific task, data set, and use case. Each of these algorithms has its strengths and weaknesses, but there are some factors that you should consider when choosing which algorithm to use:
- Data set size: FastText outperforms Word2Vec on smaller datasets.
- The number of unseen words: FastText is especially good at creating representations for words it has not seen during the training procedure, so if you expect a lot of new words that are not within the corpus of words you are training the algorithm on, then it is probably the best choice.
- Training time: Word2Vec and FastText both typically train fast, so training speed is not a factor when choosing between these two.
Each algorithm successfully identifies semantic and syntactic connections among words, so their performance levels really depend on the task at hand. Unfortunately, unless one of the previously mentioned aspects is highly significant, selecting the best algorithm involves training both and evaluating their outcomes.
In the rest of this article, I will demonstrate how these algorithms can be implemented.
How to Implement Word2Vec
There are two variants of the Word2Vec algorithm: Continuous Bag of Words (CBOW) and Skip-Gram. These two variants are similar but have some key differences. The main difference between CBOW and Skip-Gram is their approach to generating word vectors. CBOW tries to predict a target word given the context words surrounding it, while Skip-Gram tries to predict the context words given a target word.
The difference between implementing CBOW and Skip-Gram is almost negligible in terms of code, as you will see in the example below. For the purposes of demonstration, I will use the CBOW method and the Skip-Gram method to create word embeddings for words that appear in a modified version of the data set you can find right here: https://www.kaggle.com/datasets/zynicide/wine-reviews.
First, I will import everything I will use in this example:
import pandas as pd
from gensim.models import Word2VecDo take note that if you don't have Gensim installed, you can do so by running the following:
pip install gensimAfter importing everything, I will load the modified data set for this demonstration from this link: https://edlitera-datasets.s3.amazonaws.com/wine_descriptions.csv.
After loading my data, I will look at the first five rows.
# Import data and create a DataFrame
link = "https://edlitera-datasets.s3.amazonaws.com/wine_descriptions.csv"
df = pd.read_csv(link)
# Take a look at the first 5 rows
df.head()
By running the code above, I’ll get the following result:
The Kaggle Wine Reviews dataset showing descriptions of different wines.
Image Source: Edlitera
My data consists of one column, which contains descriptions of various wines. Typically I would perform some text preprocessing after loading in my data, but in this case, the data has already been preprocessed. This means I can move on and prepare to feed my data to the Word2Vec model.
Before feeding my data to a Word2Vec model, I need to convert it into a list of sentences because that is the input the Gensim Word2Vec model expects. Essentially, I want to split each sentence into a list of words and then create one big list consisting of these smaller lists representing each sentence.
To do so, I will do the following:
# Create a list of lists
# Every sublist contains a tokenized sentence
sentences = [row.split(".") for row in df["description"]]
sentences_tokenized = [sublist[0].split() for sublist in sentences]The data I will feed into the model is stored inside the sentences_tokenized variable. I’ll display just the first sentence from that list of sub-lists to see what the wine descriptions look like right now:
# Display the first sentence
sentences_tokenized[0]Running the code above will return the following result:
List of words created from the Kaggle Wine Reviews dataset.
Image Source: Edlitera
Now that my data is ready, I can feed it into a Word2Vec model. In Gensim, the Word2Vec model is represented as a Word2Vec object. This object can be trained on a list of sentences where each sentence is a list of words. During training, the Word2Vec model learns vector representations in the form of word embeddings for each word in the corpus by predicting the context words that appear near each target word.
The most critical parameters of the model are:
- vector_size: The dimensionality of the word vectors.
- window: The context window used by the algorithm to predict the context words given a target word.
- min_count: The minimum number of times a word needs to appear in the corpus for it to be included in the vocabulary.
- sg: The training algorithm to use, 0 for CBOW or 1 for Skip-Gram.
I’ll create a model, define values for the parameters and train the model:
# Create a Word2Vec model and train it
model_word2vec = Word2Vec(sentences_tokenized,
min_count=3,
vector_size=100,
window=3,
sg=0)The code above will both define the model and train it. After training the model, I first need to access the wv attribute, which contains the word vectors. After accessing this attribute, I can do a few different things, for example:
- Access the vector that represents a word.
- Calculate the similarity between two words.
- Find words most similar to some word based on their word vector values.
How to Access a Word Vector in a Word2Vec Model
I can use the get_vector() method to extract the vectors representing words and it only needs the word I’m interested in as input. I’ll use the get_vector() method to find the word vector of the word "tangerine:"
# Extract the vector that represents the word "tangerine"
model_word2vec.wv.get_vector("tangerine")The result I get by running the code above is:
An array with 100-dimensional vector representation for the word "tangerine."
Image Source: Edlitera
As you can see above, I got back an array containing the 100-dimensional vector representing the word "tangerine."
How to Calculate the Similarity Between Two Words in Word2Vec
To calculate the similarity between two words, I can use the similarity() method, which only requires the pair of words I wish to compare for their degree of similarity as input.
I’ll calculate the similarity of the words "tangerine" and "citrus:"
# Calculate the similarity between the words "tangerine" and "citrus"
model_word2vec.wv.similarity("tangerine", "citrus")The result I get by running the code above is 0.73379236, meaning the words "tangerine" and "citrus" are very similar.
How to Find Words Most Similar to a Particular Word with Word2Vec
To find which words are most similar to a specific word, I can use the most_similar() method. This method only requires one input: the word that I want to find the most similar words to. By default, Word2Vec will give you the ten most similar words:
# Find the words most similar to the word "tangerine"
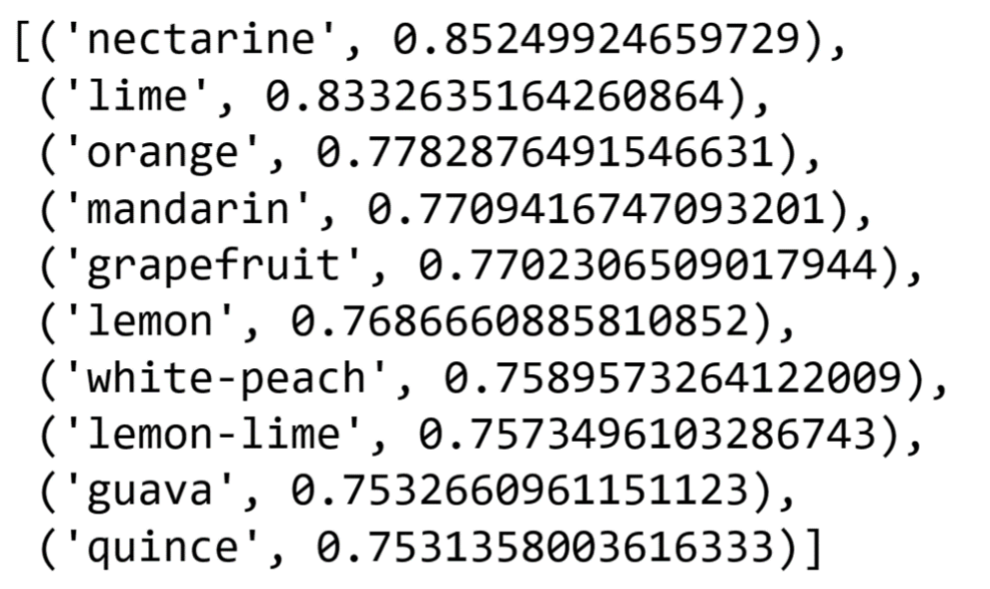
model_word2vec.wv.most_similar("tangerine")The result I get by running the code above is:
A list of similar words from the Kaggle Wine Reviews dataset found using Word2Vec.
Image Source: Edlitera
How to Implement FastText
The implementation of the FastText algorithm is almost identical to the implementation of the Word2Vec algorithm, which makes sense since FastText is an extension of Word2Vec. FastText is also a neural network -based algorithm for learning word embeddings, and just like the Word2Vec algorithm, it includes both a CBOW version and a Skip-Gram version. I won't explain the algorithm in detail in this article, but I will tell you about the main differences between the FastText algorithm and the Word2Vec algorithm because it is where the difference in implementation between the two algorithms lies.
As a word embedding model, FastText learns the meaning of words by looking at both the whole word and its subparts, called "character n-grams." This means that FastText creates vectors not only for entire words, but also for each of their constituent character n-grams. To form a vector representation for each word, the model first learns embeddings for each unique n-gram in the training corpus and then combines these embeddings to create a vector representation for each word.
For example, consider the word "apple." FastText will generate embeddings for each of the character n-grams in the word, such as "ap," "pp," "pl," "le," "app," "ppl," "ple," and "appl." These n-gram embeddings are then combined to form a vector representation for the word "apple," which captures the meaning of the whole word and its constituent parts.
When implementing FastText, you need to define the following parameters:
- vector_size: The dimensionality of the word vectors.
- window: The context window used by the algorithm to predict the context words given a target word.
- min_count: The minimum number of times a word needs to appear in the corpus to be included in the vocabulary.
- sg: The training algorithm to use (0 for CBOW or 1 for Skip-Gram).
- min_n and max_n: The range of n-gram sizes to use when constructing the word representations.
- bucket: The number of buckets to use for hashing n-grams during training (larger values increase the model's accuracy at the cost of increased training time and memory usage).
First, let's import the FastText algorithm from Gensim:
from gensim.models import FastTextNow I just need to create a FastText model and train it. To do so, I will use code almost identical to the code I used for Word2Vec. The only difference is that I need to set values for the min_n, max_n, and bucket parameters.
I’ll use a CBOW variant so that I can later compare the results with the results I got using the Word2Vec model.
# Create a FastText model and train it
model_fast_text = FastText(sentences_tokenized,
min_count=3,
vector_size=100,
min_n=3,
max_n=6,
window=3,
sg=0,
bucket=2000000)This is where the differences between the two models end. If I want to extract a word vector, check for the most similar word to a particular word, or check the similarity between two words, I can use the same methods I used with the Word2Vec model.
Let's see what I get when I search for the words most similar to "tangerine" and compare the result to the result I got when I used the Word2Vec model.
# Find the words most similar to the word "tangerine"
model_fast_text.wv.most_similar("tangerine")The result I get by running the code above is:
The results of finding similar words to "tangerine" from the Kaggle Wine Reviews dataset using the FastText algorithm.
Image Source: Edlitera
One difference is immediately noticeable: the FastText algorithm can recognize that the words such as "tangerine-laced" and "tangerine-inflected" are very similar to the word "tangerine," unlike the Word2Vec model. This is because the FastText algorithm creates the final word vector by combining the vectors it creates for n-grams.
In contrast, the Word2Vec algorithm looks at the whole word without breaking it down into parts, which makes recognizing patterns much harder. In many situations, the word embeddings created with FastText are superior to those created by Word2Vec.
After reading this brief overview of the two most popular Gensim word embedding algorithms, you can probably appreciate that when you're dealing with a broad and general text, you don’t necessarily need to train your own word embeddings and can instead make use of pre-trained ones. However, suppose your data is very specific to your field of work and contains many unique words that aren't commonly used elsewhere. In that case, pre-trained embeddings may not be effective and it would be better to train your own word embeddings. In that case, you can simply follow the steps I used above to create custom word embeddings based on your data set.

