


















Table of Contents
Welcome back to the last article in my Intro to Programming series. In this article, I'll start exploring files and how to work with them programmatically. Specifically, I'll talk about what files are, what memory is, and how to NOT crash your computer.
- Intro to Programming: Why Beginners Should Start With Python
- Intro to Programming: What Are For-Loops in Python?
What Are the Disadvantages of Using input()?
So far, I have only discussed one way to get input data into programs: reading it from users using the input() function.
That, of course, works for small amounts of data, but it has certain disadvantages. First of all, people get tired of entering large amounts of data by answering questions. In addition, what happens if the user has to answer 20 questions, but realizes that they made a mistake on question 18? They have to restart the program and go through all of those questions again. Using the input() method is slow and error-prone. Also, more importantly, input data is not saved. If you restart the program and you want to run it with the same input, or just slightly different input, you have to go through all the questions again.
So, really, you should only use the input() function to get one-off input data into your program. You would not load a store inventory using questions and answers because that would take forever and, if your program crashed, you'd have to do it all over again. But you could use the input() function to ask a user for their name, for example.
If you need to get larger, more structured data into your program, a better solution is to use files.
What Are the Advantages of Using Files in Python?
Files have a few advantages: they have specific formats, which can be understood by many programs. For example, if your accountant uses a Microsoft Excel file, that same Excel file can also be opened in Google Docs, and can also be opened by a Python program. The format of the file is well documented, so many programs can use it. Files are also very portable - meaning, you can send a friend a file, perhaps by sharing it via Dropbox or emailing it. Also, files can be stored long-term, either on your local hard drive or somewhere in the Cloud.
What is a File System?
All modern computer systems use files to organize data. Because of this, all computers use something called a file system, which is really just some computer code that's responsible for controlling how data is stored into files and how it's retrieved from files. Without files and the file system, all the data on your computer would be one giant data soup, and it would be impossible to tell where one thing ends and another begins.
I won't go into details about the file system - I'm just going over these terms, because I think it's important to have a mental model for these concepts even if it's a simple one.
Why Files are Stored on Hard Drives
Fundamentally, what you need to remember is that files are pieces of data organized in a specific format, which are generally stored on a computer hard drive (can be either your computer's hard drive or some hard drive in the Cloud). The hard drive is like the human long-term memory. It saves things to be used in the future.
Article continues below
Want to learn more? Check out some of our courses:
Why Most Computer Programs Run in RAM
However, you also need to be aware that computer programs run inside what we call the RAM, which is short for random access memory. The RAM is the computer's short-term memory. If things in RAM don't get saved to the hard drive, they won't be remembered. It's the same with humans. You can store some things in your short-term memory, but if you don't commit it to long-term memory, you won't be able to remember it. With computers, RAM typically gets cleared, for example, when the computer restarts. That's how you lose unsaved work: when you make some changes to a file, but you forget to save it, those changes only exist in RAM. Then, when your computer crashes and you restart it, you won't find it in the file because it wasn't saved in the long-term memory.
Why RAM is Super Fast, But Small
RAM is fast but small. I'm simplifying things a bit here, but that's the general gist of it. To understand the reason why, it is important to be aware of this distinction between RAM and hard drives. I mentioned earlier that computer programs generally run in RAM. They do that because RAM is super fast, but RAM is also small. Much faster than hard drives, much smaller than hard drives, too, and this is the really important thing to remember: when your program opens a file and reads it, it loads parts, or all of it, in RAM.
So, what can happen here? If your program is trying to open a huge file, it will have to basically copy all of it, or at least parts of it, from long-term memory to short-term memory, from hard drive to RAM. If the data that gets copied in the process is huge, it may end up taking up all your RAM, and that's how your computer can become very slow, because there's just not enough free RAM left for other programs to run properly, or, it can even crash. So, basically, this is why very large files can be an issue when using them in your programs.
This is just an introduction, but it's important to keep these details in mind. They will come in handy at some point in the future.
Next, I'm going to talk about the ways in which Python allows you to interact with files.
How to Open a File in Python
The first thing I'm going to look at is how to open a file. To do that, you use the open function. The open function, in its simplest form, takes just a single input.
Image Source: Edlitera
That is the string representing the path of the file you're trying to open.
Image Source: Edlitera
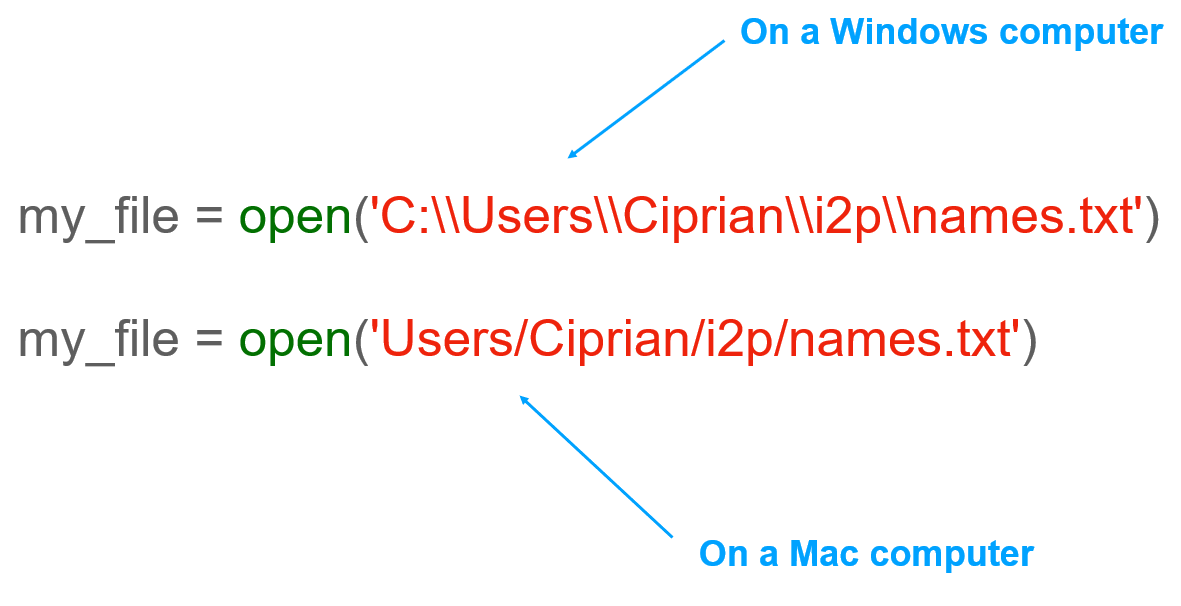
When it comes to the file path, you need to be aware of one important distinction between Windows and Mac or Linux machines.
More specifically, when you write Windows paths as strings, you need to use two backslashes (\\), not just one. So, you can see here that the first two examples, which are correct. Both use two backslashes, not just one. The reason for this is that, if you recall from the lessons on strings, one backslash followed by a letter is used to represent special characters.
Image Source: Edlitera
For example, in the first incorrect example here, the '\n' is treated by Python as a newline character.
You can get around that by using two backslashes (\\).
Image Source: Edlitera
More generally, whenever you want to actually represent a backslash character inside a Python string, you need to write two backslashes (\\). Mac and Linux paths are a bit simpler because they actually use forward slashes (//), not backslashes (\\). Here are some examples of paths pointing at files on a Mac or Linux machine. It's important to be aware of the different ways that file paths are represented on different systems.
Image Source: Edlitera
Why It's a Bad Idea to Hard-Code File Paths
One other thing I want to point out is that, generally, it's a bad idea to hard-code file paths in your code. Why is that? Well, because when you write computer code, you generally want to make sure that it runs on as many other computers as possible. That is, you want to make sure your programs are portable so that you can take them with you to a different computer. You already know that you can take files with you to a different computer, so it makes sense that you want to make sure your code also runs on different computers.
Image Source: Edlitera
The problem is that if you include a specific path, like this one, if I go to a computer that doesn't have a user named Ciprian, the program will crash. That's because when it tries to open the file at that specific path, it won't be able to find it.
Image Source: Edlitera
So what should you do instead? There are actually several alternative ways, but, for now, the simplest ones are these two.
The first option is to prompt the user to specify the path that your program needs. For example, you can use the input() function to ask the user to tell you where on their computer the file named names.txt is located.
The second option is to copy the file to the same folder where your program is running. So, if you're running a Jupyter notebook, you can copy it to the same folder where the Jupyter notebook is located. If you have a script that you wrote using a code editor like Atom or Sublime, you can copy the files you need to the same folder where the script is saved. That works because of this simple trick: if the file you need, say names.txt, is located in the same folder as the program that needs it, instead of specifying the whole path you can simply type open('names.txt').
Image Source: Edlitera
When Python sees that, it assumes that the file called names.txt is in the same folder as the program you wrote, so it doesn't actually need to know the whole path to the file because it can just look inside the folder to find it.
Image Source: Edlitera
If you wanted to open these files, you'd do something like this. If you're running your program on a Windows computer, you'd use the first version of the file path. If you're running your program on a Mac or Linux computer, you'd use the second version of the path.
Image Source: Edlitera
So, what happens when you run these commands? Basically, when you execute the open function, what it returns is not yet the contents of the file, but rather an object that represents the file.
What is an object? At a high level, objects are just data structures, which are used to programmatically represent some real-world concept. The important thing about objects is that they have methods attached to them. A list, if you recall, is an object. It represents the real-world concept of a list, and you've seen that it has some methods attached to it. One example of a list method is the append method, which can be used to add new elements to a list.
Similarly, when you run the open function, what you get back is an object that represents the real-world concept of a file. You basically get some data that represents the object. That object does not include the contents of the file by default. Can you guess why that is so? That's because there are actually multiple ways to read the content and to represent it. More on that in just a moment.
Image Source: Edlitera
So, after you run this line of code, my_file is a variable that stores some data that represents the file you want to work with. It's a bit like how the floorplan of a house is not the house itself, but rather just a representation of a house. The floorplan still gives you important information, like what's the area of the house, how many floors it has, where are the fire exits, etc.
Image Source: Edlitera
This file object actually has methods attached that allow you to read the contents of the file. The read() method reads the file and returns a string that has the whole file content. The readlines() method reads the file and returns a list where each item is a line inside the file. You'll see these in action shortly.
Next up, I'll look at how to write data to a file programmatically.
How to Write to a File in Python
We saw how we can read files programmatically. But how do we write to files?
Image Source: Edlitera
To learn that, you'll have to briefly revisit the open function. Namely, it's time to learn that the open function also takes another form, shown here. Specifically, it has an optional parameter called mode, which allows you to tell Python what you want to do with the file: Do you just want to read from it? Do you want to overwrite it? Do you want to append some lines at the bottom? Do you want to both read and write? You make the distinction between these different scenarios by setting the file open(mode) parameter.
What Are the Different Modes to Open a File in?
Why are there multiple modes of opening a file to begin with? Why not allow both reading() and writing() by default and not worry about it? That has to do with permissions.
Sometimes, you need to write code that only reads a file. Maybe it's a super important file and you want to make sure that your program doesn't accidentally overwrite it. Or, similarly, maybe you want to make sure that, when someone else uses your program, they can only append to a file, but they don't have permission to read the file, for security reasons. Python supports all those scenarios by allowing you to specifically indicate how you want the file in question to be used.
Image Source: Edlitera
The mode parameter can take these values. If no value is specified, as you've seen so far, the file is opened as read-only. That means that your program can read it, but can't write on it. The same thing happens if you do specify the mode, but you set it to the string r, which is short for read. In both of these cases, if the file doesn't exist, you'll get an error.
If you set the mode to the string r+, the file will be opened for both reading and appending. However, by default, appending will be done in the beginning of the file in this mode. Also, if you use this mode and the file does not exist, you'll get an error.
If you specify the mode and we set it to the string w, short for write, the file will be created if it doesn't exist. If it does exist, its contents will be deleted. This mode allows you to replace an old file with a completely new file, but it doesn't allow you to read the file.
If you set the mode to the string w+, the file will be opened for overwriting and for reading. That means that, if the file doesn't exist, it will get created, and if it does exist, it will get overwritten. The file will also be available for reading.
If you set the mode to the string a, short for append, the file will be opened for appending. That means that you won't be able to read the file, but you'll be able to add new content at the end. If you use this mode and you specify a path for a file that doesn't exist, a blank file will first be created.
Finally, if you set the mode to the string a+, the file will be opened for both reading and appending at the end.
Now, you don't have to memorize these. If you forget what each mode does, you can always check the documentation, or do a Google search to find which mode you should use to achieve what you want. In the beginning, a good mode to default to is a+ because it allows you to read the file and, if you write new content to the file, the content gets added at the end. This mode probably has the fewest surprises when you use it.
Image Source: Edlitera
Now, with this information, you can use the open function to open a file and write to it. You do that by using code that looks like what you can see here. You simply specify the mode as a string, right after the path. In this case, you're using the a+ mode.
Image Source: Edlitera
Just like before, the open function returns a file object, which is just a representation of the file you want to work with. In addition to read() and readlines(), this file object also has methods for facilitating writing to the file. Namely, you can use the write() function to write some string to the file, and you can use writelines() to write each of the items of a list. So write() always needs a string as an input and writelines() needs a list of strings as an input.
How to Close a File
Finally, before you quickly see all of this in action, I want to make you aware of a very important thing: if you use the open function to open a file, you absolutely need to use the close function to close the file once you're done with it.
Image Source: Edlitera
If you don't do that, you can run into some issues. The reason is this: when you use the open() function, you basically tell the file system that you're using that file. The file system says: "Ah, ok, you're using it, so I'm not going to allow other programs to change it while you use it." If you forget to close the file when you're done with it, and your program's still running, other programs won't be permitted access to the file, even though you no longer need it. So let's say you write a text file, but you forget to close it in your program. If you want to open it in say, Notepad or Atom, there's a chance you won't be able to do that because you didn't close it.
You might have already experienced this behavior before, actually. If you ever had a file opened in, say, Microsoft Word, but forgot that you have it opened and instead tried to delete it, you probably got an error telling you that the file can't be deleted because Microsoft Word is using it. That's the File System being nice, and coordinating file access for us. So, just remember to close the file.
Image Source: Edlitera
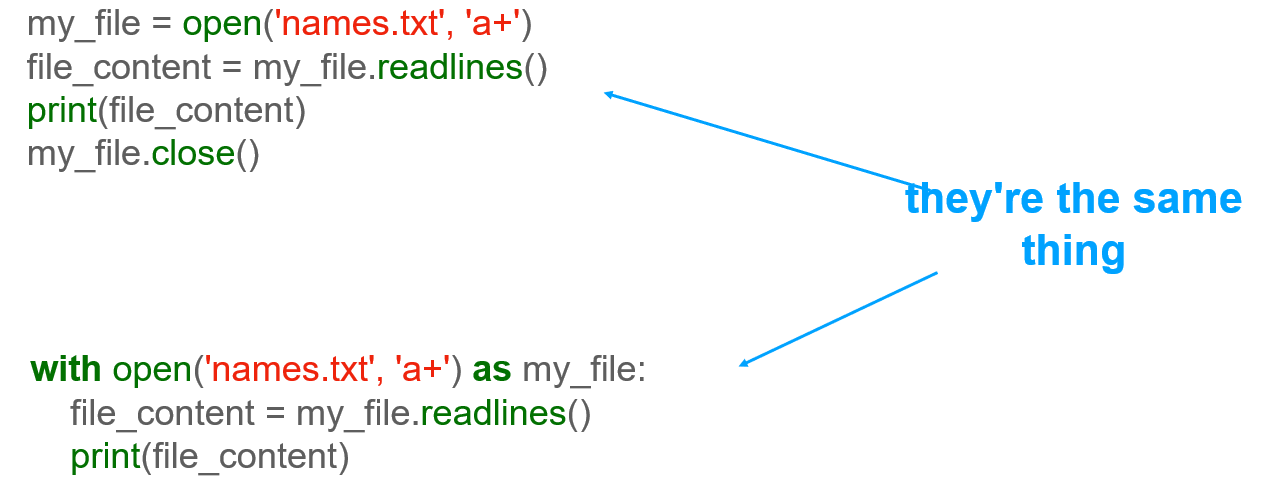
But hey, remembering to use the close() function when you're done with a file is kind of annoying, isn't it? You're only human, what if you just forget? Luckily, the creators of the Python programming language are also only human, so they thought about it. To make file closing easier, they built the with clause.
At the top here, you can see how I've been using the open function so far. You basically execute it, and you assign the file object that it returns to a variable. Then, you use that file object to, for example, read all the lines from the file and store them as a string inside a variable called file_content. Then you print the file_content variable, which, essentially, prints the contents of the file you just opened. Then, once you're all done with the file, you run the close() method to close the file.
The bottom is a simpler way to do that. You use the with keyword, followed by the same execution of the open() function, and then you use the as keyword to assign the result to a variable called my_file. This line achieves the exact same thing as the open function line above: it executes the open() function and stores a file object representing the file you want to work with in the variable called my_file.
Also, notice the colon here at the end. You need that colon because what follows below is an indented block of code. You already know what this means that you use the 4 spaces, or 1 tab indentation, to tell Python that the code below is to be considered as part of the with clause. So similarly, inside the with close, you read all the lines in your file and store them as a string inside a variable called file_content. Then, you print(file_content).
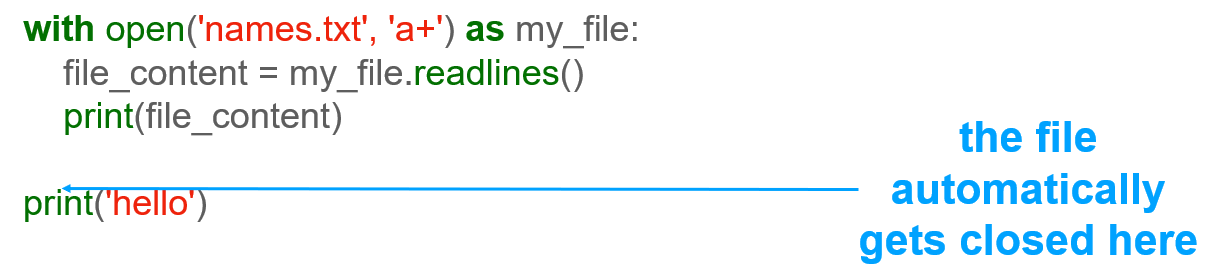
Notice what's missing here? It's the close function. How come? Well, what happens is that, once the with clause is finished, Python automatically closes the file for you. So, rather than having to remember to call the close() function ourselves, all you need to do is use the with clause to wrap all the code that works with a file.
Image Source: Edlitera
Here, you can see that, by the time you get to the print('hello') line, the file has already been closed. The print('hello') line is NOT inside the with statement because it doesn't have the indentation.
This is quite a bit, so feel free to take a moment and reread parts of the concepts that you don't fully understand yet. Next, I'll dive in and write some code that works with files.
How to Open and Read a File
Let's get hands-on with files, and play with opening and reading files using Python.
I've already created a file called names.txt, and I've placed it in the same directory as my Jupyter notebook. By the way, if you're unsure of where your Jupyter notebook is located, you can just type pwd inside a new cell and run it.
# We can type pwd into a cell
pwd
# and Jupyter will return the current path that the notebook is saved on.Ok, so let's see what's inside my names file. I can just type my_file = open('names.txt') print(my_file.read()). I don't need to specify a path because I know that this file is in the same folder as my Jupyter notebook. I'm also not specifying a mode, because I'm only reading from the file for now, and the default mode is r.
On the second line, I'm reading the content of the file using the read method, and printing it - all at the same time. Remember that when you have nested functions like these, the inner-most one gets executed first and the result of it gets passed to the outer one. So, in this case, my_file.read() will be executed first, and the result of that will be passed as input to the print() function, which will be executed second.
# Let's run and print our file
my_file = open('names.txt')
print(my_file.read())
# Our output is:
# Sylvester
# Bugs Bunny
# Tom
# JerryCool, looks like names.txt has a bunch of cartoon character names.
Now, I want to show you something that can be a little tricky to grasp at first, so listen closely. Notice that, since I haven't yet closed the file, I technically still have the file object available to me. What happens if I try to run the read() method again? Let's try it.
Hm, strange, looks like now, print(my_file.read()) returns nothing. Why is that? To understand this result, it helps if you imagine a cursor. When you open the file, the cursor is at the beginning of the file. But once you've read the whole file, you basically scrolled all the way to the end of the file. So, what happens if you now try to read again while you're at the end of the file? Well, nothing - you're at the end of the file, so there's nothing left to read.
# If we try to run the read() function a second time:
print(my_file.read())
# nothing is returnedThat's exactly what's happening here. After I called the method read() the first time, I've basically read the whole file and scrolled all the way to the end. So now, when I call it again, I get nothing because my cursor is at the end of the file, and there's nothing left to read from that point on.
How to Use the Seek Method
But, what if you absolutely need to read it again? In that case, you would need to "scroll up," or seek the beginning of the file again. Or, of course, you could close the file and reopen it again, but that would be unnecessary and kind of annoying. Luckily, there's a better way to move to the beginning of a file again. That's the seek method.
If you just type my_file.seek(), you can now type Shift + Tab inside the Jupyter notebook, and you see this helpful message telling you how to use the method. By the way, you'll need to press Shift + Tab twice in order to get the extended version of the help message. So here, you can see that seek() can be used to change your current position in the file. You can pass the integer 0 to seek() in order to move back to the beginning of the file.
Let's do that. So, I'll change this code to my_file.seek(0) and run it. Now, if I run print(my_file.read()), I get the whole file content again.
# Let's use the seek function to go back to the beginning of our file
my_file.seek(0)
# Now when we print(my_file.read()):
print(my_file.read())
# we get the same output as before:
# Sylvester
# Bugs Bunny
# Tom
# JerryPerfect. Now, I can close the file using my_file.close(). Once the file is closed, I can no longer read from it.
So, if I try to run my_file.read() again, I get an error telling me that I'm attempting an "I/O operation on a closed file," which is not possible. "I/O" stands for input/output, or basically read/write. You'll come across this term quite often, so try to remember it.
# When we close our file
my_file.close()
# and then try to read it again
my_file.read()
# we get the following error:
#␣
#---------------------------------------------------------------------------
#ValueError Traceback (most recent call last)
#<ipython-input-7-2b1e0f30a114> in <module>
#----> 1 my_file.read()
#ValueError: I/O operation on closed file.Let's now open the file using the with clause and, instead of reading the whole file in a string, I'll use the readlines() method. So I'll write: with open('names.txt') as my_file: lines = my_file.readlines() for line in lines: print(line + "---"). See if you can figure out what this code does.
Basically, I opened the file called names.txt and stored the resulting file object in a variable called my_file. This is just a variable name, so you can use whatever other name you want here.
Inside the with clause, I can now read all the lines from the file using the readlines() method. Remember that readlines() returns a list of strings, and that each item in that list represents one line in the file. So, what can I do with this list? Well, lists are sequences of items, so they are iterable. This means that I can go through the list one-by-one, and do something with each item.
In this case, I'm iterating over the elements in the list, that is to say, I'm going through each of the lines in the file, one at a time, and for each of them, I print the line, followed by three dashes. If I run this, I can see the result:
# Let's copy our file and use .readlines()
# After each line, we'll add ---
with open('names.txt') as my_file:
lines = my_file.readlines()
for line in lines:
print(line + "---")
# Our output is the following:
# Sylvester
# ---
# Bugs Bunny
# ---
# Tom
# ---
# Jerry
# ---This is a nice example that uses several things that you've learned: I opened a file, read the contents in a list, and iterated through that list. Actually, you'll see this pattern quite often as you code more. Let's do something more useful with it. What if you want to read a file and print all the lines in uppercase?
Simple, right? You may remember from strings that you can use the upper() method to change a string to uppercase.
So, you can just write: with open('names.txt') as my_file: lines = my_file.readlines() for line in lines: print(line.upper()). Just like before, you basically open the file names.txt for reading, and you store the file object in a variable called my_file. Then, you use that variable to get all the lines from the file, and you store them in another variable, called lines. So, the variable lines stores a list. Then, you can iterate through that list, and for each item in the list, you can just print it in uppercase.
# Let's iterate through our file and uppercase every character
with open('names.txt') as my_file:
lines = my_file.readlines()
for line in lines:
print(line.upper())
# Our output is now
# SYLVESTER
# BUGS BUNNY
# TOM
# JERRYNow, why is there an extra line between the names?
To understand that, you need to remember that each line in a file ends in a newline character. You typically don't think of the newline as a special character in day-to-day life. When you're typing something in a text editor, the newline just kinda happens automagically when you press Enter. But Python doesn't really work like that.
When it comes to text, it only works with strings. If a string has multiple lines, it needs a way to indicate where a new line starts. It achieves that by using the special newline character, which you've encountered before. It's the \n. For example, if you printprint('hello\nmy name is bugs bunny'), you can see that after the word hello, a new line is created and the text my name is bugs bunny appears on that new line. How did Python know that it should do that? Simple. After the word hello, you wrote that \n character.
By the way, you can't avoid using that character if you want to write something on a new line. If you try to run the code:
print('hello
my name is bugs bunny')
you'll actually get an error because you're basically breaking up a single line of code incorrectly, which is not valid Python syntax.
Ok, so back to my list of uppercase names. Each line in the file basically ends in a newline, which is this \n character. In addition, when I use the print method to print something on the screen, it too adds a newline after the string it needs to print. So that's the equivalent of running print('hello\n\nmy name is bugs bunny').
There are now two newline characters, between the text hello and the text my name is bugs bunny. That's exactly what's happening with my uppercase names too, and why I have an extra line between them.
Next, I'll look at how and where you can write in a file programmatically.
How to Open and Write to a File
So far I've only talked about reading files. Let's see a few examples of writing to files.
First, I'll append another cartoon character name to my file. Let's say Popeye. I can do that simply: with open('names.txt', 'a') as my_file: my_file.write('Popeye'). Notice that, this time, I had to specify the mode I wanted, which is a for append. If I now read the file, with open('names.txt') as my_file: print(my_file.read()), you can see that I have Popeye at the end.
# Let's use append to add Popeye to our list:
with open('names.txt', 'a') as my_file:
my_file.write('Popeye')
#Now when we read our file again:
with open('names.txt') as my_file:
print(my_file.read())
# we see that Popeye was appended
#Sylvester
#Bugs Bunny
#Tom
#Jerry
#PopeyeLet me also quickly show you what happens if you try an action that's not permitted. For example, let's say that I open my names.txt file for appending, but I try to read from it. So, I'll try to run with open('names.txt', 'a') as my_file: print(my_file.read()) and I get an error. Specifically, I get an UnsupportedOperation exception, with the message not supported. This is trying to tell me that I've attempted some operation on the file - in this case reading from it - which is not supported, because I opened the file for appending only.
# If we try to read our file after opening it with a:
with open('names.txt', 'a') as my_file:
print(my_file.read())
# We get an error message
#␣
#,!---------------------------------------------------------------------------
#UnsupportedOperation Traceback (most recent call last)
#<ipython-input-15-c24f1912960b> in <module>
#1 with open('names.txt', 'a') as my_file:
#----> 2 print(my_file.read())
#UnsupportedOperation: not readableI'll go over one more example, this time a bit more complex.
Oftentimes, what you need to do with files is read them, and then change them in some manner. For example, say someone asks you to write a program that reads a file containing names of cartoon characters, and wants you to change the file such that you add the names in uppercase at the end of the file.
No problem. Whenever you hear that you have to modify existing content inside a file, you know that you'll need to be able to both read the file and write to it. In this case, you're trying to read the content of the file, and then append some new content at the end. So, it looks like the mode you want is r+. Let's write the code: with open('names.txt', 'r+') as my_file: lines = my_file.readlines() for line in lines: my_file.write(line.upper()).
To summarize, you opened the file, you read all the lines, and you stored them in a list variable called lines. Each line is now a string inside the lines list. Then, you iterated through each of those lines, and you appended the uppercase version of it to the end of the file.
If you now open the file and read it: with open('names.txt') as my_file: print(my_file.read()), you can see that you have both the lowercase and the uppercase versions of the names.
# Let's append a list with uppercase characters to our original list
# We'll need to read and write, so let's use r+
with open('names.txt', 'r+') as my_file:
lines = my_file.readlines()
for line in lines:
my_file.write(line.upper())
# Now we can print the list and see the updates
with open('names.txt') as my_file:
print(my_file.read())
# Our output is now
#Sylvester
#Bugs Bunny
#Tom
#Jerry
#Popeye
#SYLVESTER
#BUGS BUNNY
#TOM
#JERRY
#POPEYEWhat would have happened if, instead of r+, we used w+? Let's try it. You can just copy-paste the code above and just replace r+ with w+. Now, again, you read the file, so you can copy-paste that part of the code too.
When you run it, you'll get nothing. Why is that? Well, remember that the modes that start with w, so both w and w+ work this way: they first open the file, then they delete any existing content from the file, and only then do they execute whatever code you want to execute. So, in your case, Python sees that you're using the w+ mode to open names.txt, so it first deletes the contents of the file, and only then starts executing our code.
Then, the first line of code inside the with clause attempts to read all the lines in the file. That's allowed, because w+ mode also supports reading. But! There are no lines in the file anymore, because the content has already been deleted. So, that line's variable contains an empty list - a list with no elements. Because the list has no elements, nothing gets uppercased, and nothing gets written, so you end up with an empty file. Not what you expected.
The various modes to open a file can be a bit tricky to fully understand at first. So, before you go and use them on important files that you would not like to lose forever, make sure you understand the differences between them by using them with toy-files that you make yourself, like the names.txt here.
That's it for the basics of working with files in Python. Knowing how to read and write files programmatically is very powerful, because much of the digital world is organized in files. Here, I only looked at plain text files, but there are Python packages out there that are specialized for working with CSV files, Excel files, images etc., and, best of all, the basic principles that you saw here will still apply, even in those cases.
As usual, the key to mastering these concepts is practice, so keep playing with Python, and keep solving problems with code. It has been a pleasure to be your guide through Edlitera's Introduction to Programming series. I hope you enjoyed it.
If you understood all that I discussed in these articles, you are well on your way to becoming a programmer and enjoying the wealth of opportunities that come with it. If you are still having trouble with some of the concepts, please don't give up. It may take some time, but programming is not an impossible task. Reread the articles, search the internet for alternative explanations and, more importantly, keep writing code! It doesn't matter how silly or simple this code may seem at first - it will help you get better. As you grow as a programmer, you will realize that programming is not just something you do. It becomes part of you because it changes how you think. It is an extremely rewarding activity, both financially and intellectually.
Programming is a way of thinking and a way of doing. The specific language that you use is not even that important, so don't get too discouraged if you hate some programming language or another. In fact, programming interviews nowadays rarely expect you to remember all the details of a specific language. What matters is how you think. If you master programming in one programming language, you will be able to pick up new languages very quickly - much, much quicker than your first language.
If you're looking for next steps, my first, and strongest advice, is to keep writing code. Also - very importantly - to read a lot of code. You can find lots of open source code on sites like github.com. Reading code will show you how other programmers think, how they structure their code, how they go about solving specific problems - and you can learn a lot from this. Apart from writing a lot of code and reading a lot of code, I also encourage you to take our more advanced courses, which will build on this introductory course to further enhance your skills.

