



Table of Contents
Before you can focus on leveraging data science, you need to be aware of the possible issues, commonly referred to as “pitfalls,” in data science processes. Pitfalls are particularly frustrating for businesses as they often result in no return on investment for your data science project. This article will go through a list of potential pitfalls in the data science process and how to solve them.
What is a Data Leak?
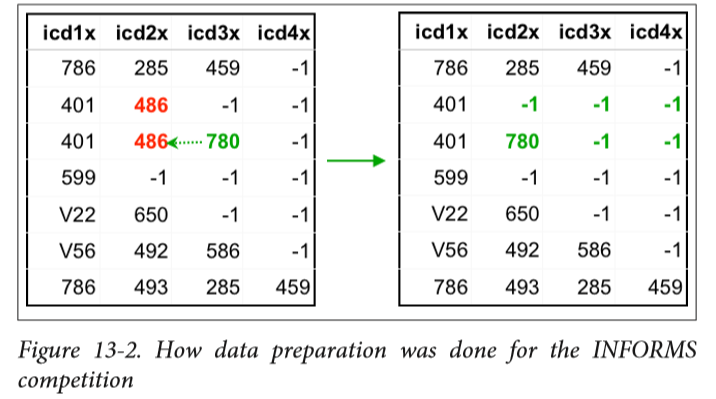
Data leakage happens while training a model, and is when a user utilizes information or data that is not supposed to be included in the training dataset, or will not be available to the model while making predictions. An example of leakage occurred during the 2010 INFORMS competition, put on by the Institute for Operations Research and Management Sciences. The challenge at the 2010 competition was to predict pneumonia admissions within hospitals. At the end of the competition, the participants found that a logistic regression with diagnosis codes as a numeric value did not perform as well as a regression with diagnosis codes as a categorical value.
Image Source: O’Neil & Schutt, Doing Data Science: Straight Talk from the Frontline, O’Reilly, 2014
The figure illustrates the method of data preparation used in the 2010 INFORMS competition. In the figure, the diagnosis code for pneumonia is 486. The rows represent different patients, while the columns are different diagnoses. If the pneumonia diagnosis showed up in the record, the code was replaced with either the next diagnosis code, or with a “-1” if no further diagnoses were made. In following this process, all other diagnoses after a pneumonia diagnosis were moved to the left in a given patient row, while “-1”s were kept to the right.
The data leakage problem using this data preparation method is that the end result of the process clearly indicates whether or not a patient was admitted to a hospital with a diagnosis of pneumonia. For example, if a row has only “-1”s, you would know that the only diagnosis for that patient was pneumonia. On the other hand, if a row has no “-1”s, it is clear that there was no pneumonia diagnosis.
This pattern created during data preparation of the numerical diagnosis codes meant that models were trained to accurately identify the pattern, and not to accurately predict pneumonia admissions, as was the original goal. The discovery of the data leakage issue alone was enough to win the INFORMS competition. Data mining competitions like this one often face the problem of data leakage.
Article continues below
Want to learn more? Check out some of our courses:
How Do You Avoid a Data Leak?
Data leakage is always a risk during data preparation, as you deal with missing values, remove outliers, or do any data operations. Even if you create a model that works well on a clean data set, it may not perform well in a real-world scenario. To avoid data leakage, always start from scratch with clean, raw data, and know how the data was produced.
How to Evaluate Your Data Models
When evaluating a model’s performance, don’t only look at standard modeling evaluation measures like misclassification rate, area under the curve (AUC), or mean squared error (MSE). Often, looking at real-world business impact metrics, such as profits, can open your horizons and provide a realistic perspective through which to evaluate your model.
- How to Evaluate Classification Models
- Data Science Success: Knowing When and How to Make Decisions Based on Data Science Results
Other problems may become evident during your model evaluation. Two common problems to watch for when evaluating models are overfitting or underfitting of the data. To avoid overfitting, reduce the complexity of the model. To fix underfitting, increase the complexity of your model.
The image shows a simple visualization of an underfit model (left), an overfit model (right), and a well fit model (middle).
Image Source: O’Neil & Schutt, Doing Data Science: Straight Talk from the Frontline, O’Reilly, 2014
How Feature Construction Helps Avoid Data Pitfalls
Data scientists often make assumptions to build features that have high predictive power. The following is a list of tips to avoid common pitfalls during feature construction:
- Keep a record of which features were generated and which features were collected.
- Remember how features were generated and what assumptions were made during generation.
- Ask yourself if the data used to generate the features will be available long-term.
- Machine Learning Styles: Most Common Types of Machine Learning and When to Use Them
- What Are Eight Critical Steps in the AI Project Life Cycle?
Any business sector—from technology to transportation to healthcare and beyond—can take advantage of the automation and learning that become possible through data science. At the same time, the opportunity for growth comes with many opportunities to make mistakes. By keeping an eye on the possible pitfalls, you’ll have a greater chance of reaping the benefits of data science for your business.

