

![[Future of Work Ep. 1] Future of Fashion: Using Data to Predict What Will Sell with Julie Evans](https://res.cloudinary.com/edlitera/image/upload/ar_16:9,c_fill,f_auto,q_auto,w_100/56ar4tdmijwmrgnhoq4f56kcoddw?_a=BACJ3SGT)
Table of Contents
- Step 1: What Problem Do You Want to Solve?
- Step 2: What Data Do You Need to Build a ML Solution?
- Step 3: What Does the Data Tell You?
- Step 4: How to Clean the Data for Machine Learning
- Step 5: How to Select Algorithms and Train Models
- Step 6: How to Compare and Pick Your Models
- Step 7: How to Fine-tune the Final Model(s)
- Step 8: How to Deploy, Monitor and Maintain the Model in Production
If you are exploring how to use machine learning and AI-based solutions in your business, you are in good company. According to Gartner, in spite of the global impact of the Covid-19 pandemic, 47% of AI investments were unchanged since the start of the pandemic, while 30% of organizations polled actually planned to increase their investments in AI.
When considering an AI solution to a business problem, you usually have two options to explore. The first is buying an off-the-shelf solution. If you can find an adequate ready-made option, this is a fine solution.
The second option is building a custom solution. This option is oftentimes preferred by companies who are serious about AI, thanks to the opportunity for precise tailor-fitting to the problem at hand. This is also thanks to the fact that custom solutions are typically more cost-effective than managed ones in the long run, even while requiring a larger investment upfront.
There is only a tiny little problem with enterprise AI projects. About 90% of them never make it to production. You read that right: 9 times out of 10, months of hard work go to waste. The reason is usually the fact that, in the excitement of getting something off the ground, steps are skipped and corners are cut.
In this article, I will discuss the eight steps that usually go into building and deploying a custom AI-based solution to a business problem. Follow all of these steps in order, and you will maximize your chances of building an AI solution that gets deployed, is used productively, and helps you maximize your return on investment.
- AI Adoption During COVID-19
- How to Create a Roadmap for the Data Science Process: A Manager's Perspective
Step 1: What Problem Do You Want to Solve?
The first and most important thing to do when building an AI solution is to describe exactly what problem you are trying to solve.
What does your ideal solution look like? In other words, imagine what the world looks like after a solution for this problem has been deployed. Will your team have to do less or no manual work to complete a task? Will you get new data and insight from a particular process faster than before?
Next, define how your solution will be used:
- Will it be scheduled to run automatically?
- Will it be an ad-hoc script that someone runs manually?
- Will it trigger an automatic action, such as adjusting a threshold in a production process or sending a coupon to a customer?
- Will it nudge someone to make a decision or do something? For instance, it could send an alert email to an engineer informing them that a system needs their attention.
Once you know how the solution will be used, it is time to figure out how to measure its performance on the task at hand. In addition to deciding which performance metric makes the most sense for the problem being addressed, you will also need to figure out what performance threshold you need to pass in order to have a useful solution.
- Automation With Machine Learning: How to Use Machine Learning to Automate a Task
- Data Science Success: Knowing When and How to Make Decisions Based on Data Science Results
Step 2: What Data Do You Need to Build a ML Solution?
The next step is understanding what kind of data you need, and where you can find it. From a business perspective, you'll need to understand what data could be useful for building your solution, where to find this data, and how to negotiate access to it.
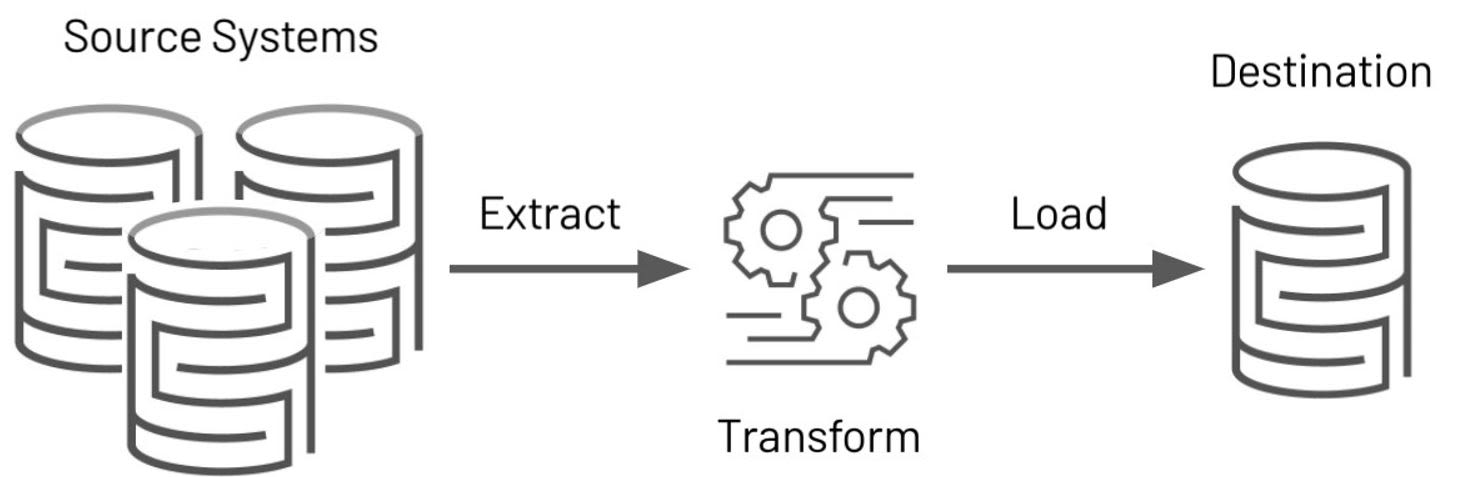
From a technology perspective, you'll want to create a workspace for your model training needs. Ideally, you want to have enough space to hold the data in one place. If this is not possible, you can build the needed ETL data pipelines to get data from your data lake as needed, and convert it to a useful format. You might also want to make sure that you have installed all the required software and packages to your machine learning workspace.
ETL Process
Image Source: ETL Infograph, https://databricks.com/glossary/extract-transform-load
Step 3: What Does the Data Tell You?
Once you have lined up your workspace and your data sources, it is time to explore the data and answer the following questions:
- What are your data attributes?
- What are the data types?
- Do you have gaps in the data? If you do, how large are they?
- How is your data distributed? Is it uniform, logarithmic, normal, or following another distribution?
- How noisy is your data? Are there lots of outliers or rounding errors, or is the data mostly clean?
If possible, it is a good idea to build some simple visualizations of your data (or a sample of it). For instance, binned histograms will help you see how your data is distributed. For supervised learning, scatter plots of pairs of variables will help you study correlations between the variables. This, in turn, will help you identify the variables that could be most predictive of your target.
Step 4: How to Clean the Data for Machine Learning
As any data professional will tell you, data cleaning is the least sexy and most time-consuming part of the machine learning process.
Article continues below
Want to learn more? Check out some of our courses:
Data Cleaning
It is usually a good idea to not modify the original data. Instead, make a copy of the data and modify the copy. Also, instead of writing ad-hoc code each time, try to write functions for data transformations, as they are more reusable.
Data cleaning can be a bit of an art, and also highly specific to each data set. However, at a minimum, you should remove outliers (or otherwise deal with them), fill in or remove missing values, and remove duplicates.
Feature Selection
Next comes the feature selection step. At this point, you should only keep those features in your data set which are relevant to your target (what you want to predict). You can go ahead and drop all other features from the data - it will save space and speed up the model training process. You will probably need to do some feature engineering and possibly feature scaling at this point. This might include converting continuous features to discrete, or creating derived features by transforming existing ones (getting ‘age’ from ‘date-of-birth’).
Feature Scaling
In terms of feature scaling, standardization means transforming your data to have a mean of 0 and a standard deviation of 1. Normalization (min-max normalization) will scale the data to have values between 0 and 1. However, normalization does not do anything to handle outliers. Standardization does help with outliers, though, which is why it is usually preferred for scaling.
Step 5: How to Select Algorithms and Train Models
If you have still have lots of data at this point it might be a good idea to sample some smaller training sets. This will allow you to test many different models faster. That said, you may still want to train neural networks and random forest algorithms on as much data as possible - a smaller training set may put these algorithms at a disadvantage.
Step 6: How to Compare and Pick Your Models
Now, you need to measure and compare the performance of the various trained models. Which are the most significant variables for each algorithm? Do they make sense? Analyze the errors made. Is there any other data that you could add to the training set that would help to avoid these errors? Select the top couple of models that look promising. The trick here is to pick those models that make different kinds of errors.
Step 7: How to Fine-tune the Final Model(s)
Use cross-validation to fine-tune hyper parameters. Hyper parameters are model-level parameters, such as the number of trees in a random forest.
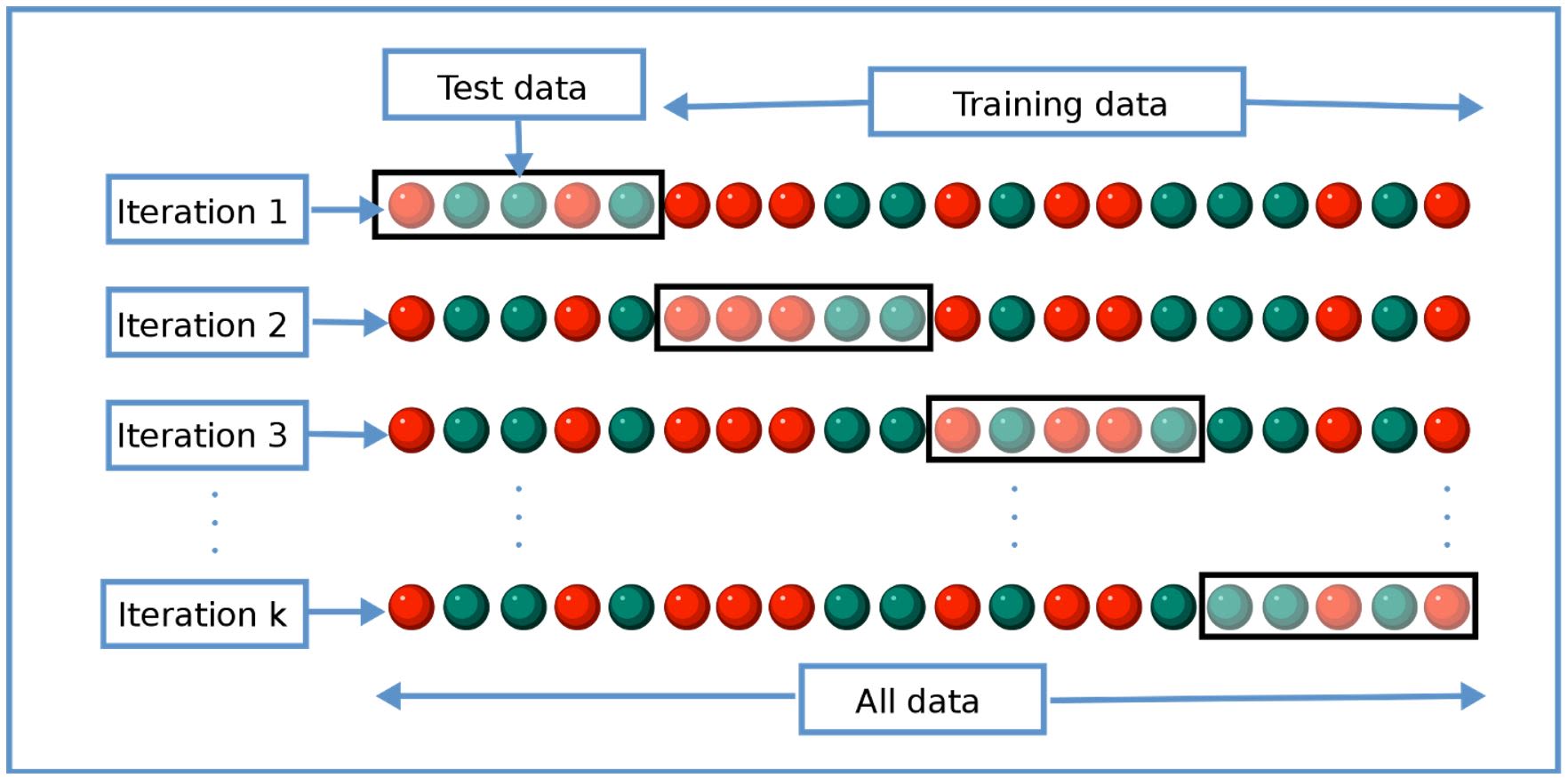
Image Source: https://en.wikipedia.org/wiki/Cross-validation_(statistics)#/media/File:K-fold_cross_validation_EN.svg
Also, try treating your data transformations as hyper parameters that you can switch on or off, or whose values you can change.
For instance, one hyper parameter can be the way you handle missing data. That way, you can retrain your model to see how it performs if you fill in missing data with, for example, all zeroes versus averages versus just dropping the rows with missing values. When you are satisfied with the model’s performance on the training set, it is time to measure its performance on a test set, and estimate the generalization error.
Step 8: How to Deploy, Monitor and Maintain the Model in Production
Congratulations! You now have a working model that more or less solves the problem you set out to solve. You might think you are done at this point, but not quite.
When it comes to deploying, monitoring and maintaining a machine learning solution in production, automation is your friend. Ideally, in addition to automating the solution itself, you should also automate the machine learning model deployment process, as well as a system to monitor the performance of your model in production. Over time, models can experience degradation in performance due to new data being introduced in the training process. Set up a production monitoring system that will alert you when the performance goes below a certain threshold. At that point, you can retrain the model to bring its performance back to optimal levels.
- What is MLOps: An Introduction
- AI for Leaders: A Practical, No-Code Intro to Machine Learning and Deep Learning
It is estimated that as much as 90% of machine learning models never make it to production. This is usually due to one or more of the steps above being skipped, or not followed properly. By following the steps outlined above, you will significantly improve the odds that your machine learning-based solution will be a useful one, as well as one that is used by its intended audience frequently and productively. If you want to learn more about the ins and outs of managing AI projects, you may find our AI for Leaders course interesting.

