



Table of Contents
- What is Machine Learning?
- What are the Core Components of Machine Learning Systems?
- How is Machine Learning Applied?
- What is Deep Learning?
- What Are the Limitations of Deep Learning?
- How is Deep Learning Applied?
- What is Artificial Intelligence?
- What Are Some Promising Leads in AI Research?
- What Challenges Face Machine Learning and AI?
As a data scientist and founder of a data technology business, I’ve sat through enough talks about AI in business to know a really good one from a cringe-fest. In a cringe-fest, it is painfully obvious that the speaker does not fully understand what they’re talking about, but they nonetheless trust that careful repetition of buzzwords, delivered with just the right amount of enthusiasm and sprinkled with a cringey joke or two will fool the audience into thinking that they are faced with an expert. Of course, this almost never works. Instead, it’s a bit like playing AI Buzzword Bingo: most people still in the room are on their phones, and I half expect the guy sitting across from me to yell out “bingo!” at any point.
Still, even for someone truly applying themselves to understanding AI and what it means for their business, it can be surprisingly difficult to pin down clear, non-circular definitions for the top buzzwords.
In this article, I'll explain the differences between machine learning, predictive modeling, deep learning, and artificial intelligence, and why AI is quite a ways away from making human intelligence obsolete.
What is Machine Learning?
Machine Learning is the use of mathematical procedures - also known as algorithms - to analyze data. The goal of machine learning is to discover useful patterns, relationships or correlations between different items of data.
For example, when you click on a song on a music streaming service, the service uses machine learning to recommend other songs by similar artists, in the same genre, or in other genres that other listeners with similar tastes to yours might have enjoyed.
Predictive modeling is the use of machine learning to make predictions. Most often, these predictions are about people’s preferences or future behaviors, but they could also be, for instance, about how soon a piece of equipment might break without preventive maintenance.
In the music streaming example, data about which music new users prefer can be used to predict and recommend new-to-them music that they might enjoy. A predictive model is the output generated by the machine learning process. The model captures the relationships or patterns in the training data, which have been uncovered by the machine learning process.
So, machine learning is a process and the predictive model is the end product of that process. The predictive model is then applied to previously unused data to generate new predictions. These predictions are eventually used to make business decisions.
That is how machines learn. Humans learn in much the same way. You, too, observe what happens around you, draw conclusions from your experiences about how the world works, apply what you have learned to new situations you find yourself in, and make increasingly better decisions the more you experience and learn.
There are several types of machine learning algorithms, each of which using a slightly different learning process:
- Statistical Approaches - have been around the longest, and include methods like linear regression, logistic regression and decision trees.
- Ensemble Methods - are simply aggregations of simpler statistical algorithms. For instance, random forest is an ensemble method which aggregates output from a high number of simple decision trees.
- Neural Networks - are a crossover concept from neuroscience. In a nutshell, neural networks are a highly simplified mathematical representation of (our current understanding of) how the human brain works. While they’ve been around for almost 80 years, neural networks have been enjoying a moment of fame for the past few years thanks to new research into deep learning.
What are the Core Components of Machine Learning Systems?
What exactly goes into a machine learning solution that can be used to solve a business problem? A machine learning solution system includes the following:
- Input Data - is a sample of data about the event you would like to predict. For instance, if you set out to predict which of a company’s website visitors are going to convert to customers, your data input would consist of a sample of the website’s visitors, along with information such as their location, visit duration, demographics, pages visited, etc. Also, you would want to know for each visitor (data point) in the sample whether they are a customer of the company or not.
- Data Pre-processing - is the process of finding and dealing with formatting errors, gaps, outliers and other irregularities in the input data that could cause an error later in the ML process, or in the logic underpinning the algorithm’s results.
- Predictive Models - are the machine learning algorithms that have been applied to the input data to extract insights about patterns. For instance, in the website visitor conversion example, you may want to know what traits do the company’s customers have in common. Then, you might also want to know which of the visitors who have not converted yet have the same traits in order to predict which of them have the highest chance of converting.
- Decision Rules - (or rule sets) are business logic put in place to make decisions based on the outputs (predictions) from the predictive models. For instance, once you have identified a group of visitors who are similar to customers but are not yet customers themselves, the company may want to engage with them through marketing in order to encourage them to convert.
- Response - is the actual, real-world action that the company takes as a result of using the machine learning system. In our example, this includes any coupons, discounts, or other marketing that the company uses to engage with those non-customer visitors to their website that have been found to be similar to paying customers (i.e., have a high likelihood to convert).
- How to Start Using Machine Learning and Artificial Intelligence: Tips for Business Leaders
- What Are the Most Common Machine Learning Styles?
How is Machine Learning Applied?
Now that you have an understanding of how machine learning is used to make predictions, let’s look at some examples of how these predictions are put to good use in the wild:
Credit Scoring
Determining someone’s likelihood to pay their debts has always been valuable information for creditors. But for most of history, it was impossible for a bank to determine how likely you’d be to default on debt. The best a potential creditor could do was try to ask a previous creditor (like your previous landlord or former bank) how often you’d pay your bills.
Though, of course, they wouldn’t get an answer like, “they are 85.7% likely to pay their bills on time, and they usually makes 48.4% of each payment,” they’d more likely get something along the lines of ,“they usually pays on time, and they're a nice enough fellow.” This all changed in the 1950s, when the first credit scoring system was introduced by Fair, Isaac and Company. This went on to become the modern FICO scoring system in 1989.
This industry standard assigns each individual a creditworthiness score from 300 to 850, based on the following factors, in this order:
- Payment history
- Amounts owed
- Length of credit history
- Types of credit used
- Recent credit inquiries
Target Marketing
Figuring out who is most likely to buy your product or service and how much they are willing to pay for it has long been the Holy Grail of entrepreneurs and marketers everywhere. Now, predictive analytics is making this not only possible, but increasingly accurate, too.
Take the French beauty company, Sephora. For the past few years, Sephora’s email marketing strategy has been based on predictive modeling. The company uses these predictions to send their customers customized emails with product recommendations based on purchase patterns of an “inner circle of loyal customers."
In short, Sephora can zero in on what its best selling products are, who is buying them and why. Then, they can turn around and sell more of those products by marketing them to other, similar customers as well.
Sephora's results?
- Doubled response rates without increasing campaign costs - at all.
- Decrease in the time needed to execute a direct mail campaign by 70%. Because they could better predict which customers were likely to buy what, a smaller number of coupons and catalogs needed to be mailed out. As in, more than two thirds fewer coupons and catalogs. Not bad.
- Campaign analysis time went from 5 days to one day. Whereas before it took a full week to measure the effectiveness of an email campaign and gather feedback from it, the targeted campaigns can now be measured in about a day. Which leaves the other four days to sell more makeup!
Insurance Pricing
If you are a data geek like me, you too might find the topic of insurance risk pricing fascinating. Take auto insurance for example. Even if both you and your neighbor drive the exact same make and model car, from the same year, you are very likely paying different amounts for auto insurance. As you probably already know, insurance comes in many flavors, priced differently for each customer based on her own, unique risk profile. While those pricing calculations were traditionally done by armies of number-crunching actuaries and underwriters, machine learning has been a boon for more accurate and granular insurance pricing.
Preventive Medicine
In medicine, machine learning is used to predict and attempt to lower the likelihood of chronic conditions like heart disease and diabetes. For instance, risk scores are computed for large samples of a population by using lab testing, biometric data, claims data, patient generated health data and relevant lifestyle data. Based on these risk scores, doctors can recommend preventative treatments or activities that can lead to dramatically improved outcomes for patients. Without using machine learning to compute these scores, it would be cost prohibitive to screen and assess such large numbers of individuals at a time.
Social Media
When selecting which post to show you next on your news feed, Facebook will take into account and weigh the following:
- Inventory - all the posts available to show you, whether from your friends, from pages you followed, or sponsored posts.
- Signals - each post in the inventory is then considered based on things like the number of likes, shares and reactions it has gotten, whether it contains a picture, video or just text, and even things like the speed of your internet connection and the type of device you are currently browsing on.
- Your Past Behavior - also plays into it, through factors like what Facebook thinks you would prefer to see on your feed, which friends’ posts you’ve engaged with most in the past, and which posts you’re most likely to hide or ignore.
Matching People on Dating Sites
Things like your likes and dislikes, how you describe yourself, your life goals, and your past activity on the dating platform are all taken into account when calculating your match score to potential mates.
Detecting Credit Card Fraud
Do you know those calls you get from your bank after a 14-hour flight, when you’re on the airport in Istanbul, or Shanghai, trying to use your debit card to get some local currency so you can pay for a cab to your hotel? Those calls are proof that your bank’s fraud detection models are working as intended. If you live in Miami, your bank expects all of your transactions to be more or less local. But if all of a sudden someone in Istanbul is trying to make a withdrawal, your bank will suspect foul play.
Decision Making
If you need to make a similar decision repeatedly, and take into account more or less the same type of data each time, machine learning can likely help.
What is Deep Learning?
Earlier, I mentioned neural networks. Neural networks are a neuroscience concept that made its way into machine learning. While they’ve been around for the past 80 years, neural nets have been enjoying a moment of fame for the past few years thanks to recent research in deep learning.
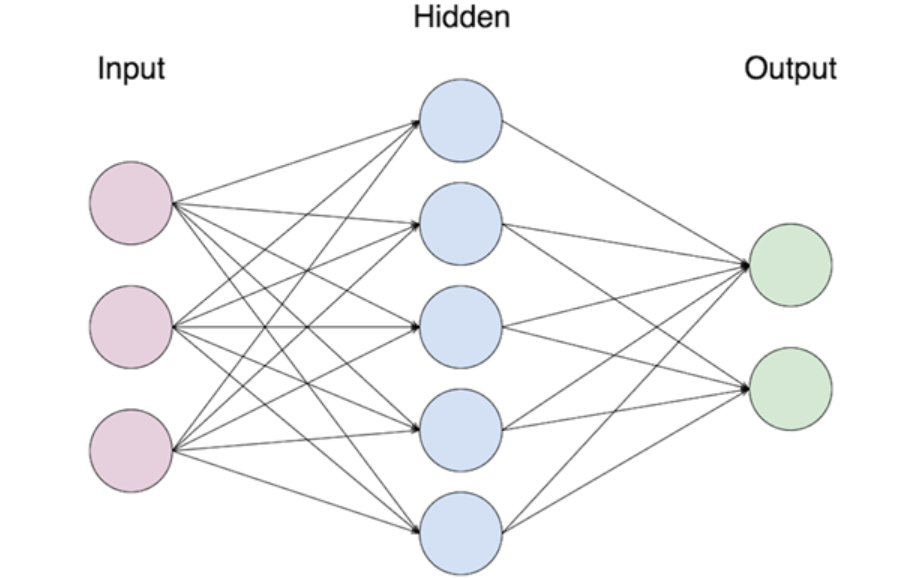
A perceptron is a very rough, simplified mathematical model of a "neuron." A neural network is made up of several perceptrons, connected together.
Image Source: Simple Neural Network, Google Images
Deep learning is done using “deep” neural networks, or neural networks with multiple “layers” of “neurons."
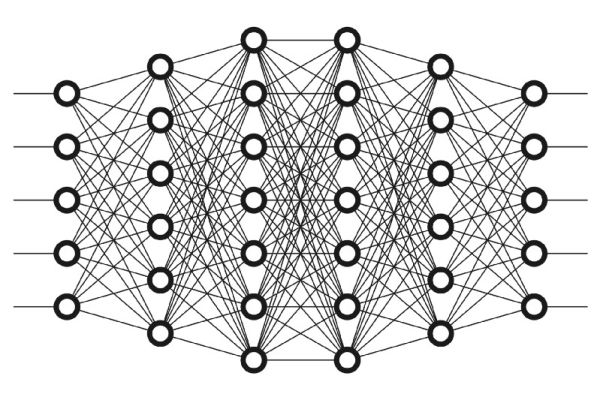
Why is deep learning so special? Research has shown that, the more layers there are in a neural network (that is, the deeper it is), the better it performs at finding complex or subtle patterns in data.
For this reason, research in neural networks is primarily concerned with the following:
- Expanding the number of layers in a network
- How individual neurons in the network are connected to one another
For example, different connection patterns give us different kinds of neural networks:
Artificial Neural Network (ANN)
A standard ANN is one in which all the neurons in the first layer are connected to all the neurons in the second layer, and so on.
Convoluted Neural Network (CNN)
A CNN is one where only some (but not all) of the inputs are sent through the neurons in the first layer. CNNs perform particularly well in image recognition problems.
Article continues below
Want to learn more? Check out some of our courses:
Reccurrent Neural Network (RNN)
A RNN is one that contains feedback loops. For instance, in a RNN, the outputs of the neurons in the last layer can act as input to the neurons in the first layer. RNNs make it possible to analyze sequence-of-events data, in which time is an important factor.
What Are the Limitations of Deep Learning?
Deep learning is the sexy new thing in AI research, and seems to do a great job solving some of the most complex problems out there. So why don’t we just abandon other machine learning techniques altogether and just use deep learning for everything?
There are a few reasons why deep learning is unlikely to make classic machine learning obsolete, at least for the foreseeable future:
Low Explainability
Deep learning models are some of the least explainable of all machine learning techniques. If you cannot see the reasoning and facts that went into making a decision, you probably won’t trust it very much.
Let’s put it this way: if your doctor recommended brain surgery without running any tests or producing any other evidence to support his decision, would you trust him? Occam’s razor dictates that, given the choice between an opaque, black-box system and a much simpler, explainable one, both of which make predictions with comparable accuracy, the simpler, more explainable one is the better bet.
High Volume of High Quality Training Data Required
Deep learning requires lots of very clean, high quality training data to work its magic, whereas some simpler techniques and ensemble methods can perform well using less data. When it comes to most business problems, it is often impossible or impractical to gather a very high volume of very clean data to train a deep learning system on.
High Computational and Financial Costs
Training a deep learning algorithm requires a lot of computational resources, which can get very expensive fast.
Deep Learning is Overkill for Some Types of Problems.
Let’s say that you can afford to spend resources on a deep learning solution to your problem AND you have lots of clean data to use, AND you are okay with low explainability. Should you go for it? In the case of many day-to-day business problems that classic machine learning can solve, using deep learning instead is simply overkill, even if it does result in a marginally more accurate model. In fact, when applying any technology in general, you should always aim to use the least complex solution that solves the problem. This is because, in the long run, very complex systems can get very expensive to maintain, even if they may not have been that expensive to develop in the first place.
How is Deep Learning Applied?
While not every problem is a good candidate for a solution using deep learning, some applications of deep learning have made outstanding progress at solving problems that were considered impossible previously.
Here are a few application of deep learning that were pretty much impossible before:
Language Translations
Not too long ago, most translation software stitched together word and phrase translations, with no regard to context. The resulting translations were not fooling anyone. Now, Google Translate uses RNNs to generate translations that are vastly improved.
Strategy Games
IBM’s Deep Blue AI beat Gary Kasparov in a game of chess for the first time in 1996. A year later, Deep Blue beat Kasparov again in a whole match. Fast-forward twenty years later, and DeepMind’s AlphaZero AI beat Stockfish 8, another AI that was considered to be the best chess player at the time. This might not seem like such a big deal until you realize that, in 2017, (1) the best chess player in the world was no longer a human, and (2) AlphaZero learned to play chess from scratch in just 4 hours, without being trained on human chess strategy patterns like other AI before it.
Self-Driving Cars
I have a confession to make: ever since I learned to drive, I have been cheering on the full automation of driving. Driving a top-of-the-line convertible through scenic landscape, with the sun behind you and the wind in your hair is fun. But the other 99.99% of the time, I only want to get from A to B on the map as fast as possible, and without having to deal with the process. Self-driving cars have made tremendous progress thanks to deep learning, with car manufacturers everywhere investing heavily in the technology.
Virtual Assistants
Understanding human language is known in the AI industry as natural language processing (NLP). Deep learning has helped NLP take huge steps in recent years, making products like Amazon’s Alexa and Apple’s Siri increasingly helpful and less frustrating for day-to-day tasks like searching for a dinner place, or finding and playing that song that’s been stuck in your head all day.
Reading Lips
In 2016, a deep-learning AI built by Google’s DeepMind vastly outperformed human experts in lip reading a difficult, unscripted BBC talk show. How vastly, you ask? Human experts who attempted to lip-read the same footage got it right 12.4% of the time. The AI got it right 46.8% of the time.
What is Artificial Intelligence?
Artificial Intelligence is human-like intelligence exhibited by a human-made algorithm. At this point in time, AI is machine learning, plus “something else”. In other words, scope makes the difference between two types of AI: narrow and general. All the applications we’ve seen so far are examples of narrow AI.
Without a doubt, narrow AI has made outstanding progress, sometimes performing better than human experts at one specific task. However, general AI, or complete, human-like artificial intelligence, is far more complex and not yet a reality.
What About Bots and People?
That said, oftentimes perception is reality. Measured by the yardstick of human perception, many a narrow AI has made a visit to uncanny valley. Machine learning has been the subject of research and applications for a pretty long time. With increasingly more complex algorithms come increasingly smarter bots, which are increasingly harder to tell apart from humans for the casual observer.
So how does one measure a bot’s similarity to a human? The Turing test, named after Alan Turing, has been used for the past 70 years to test a machine’s intelligence. The underlying assumption of the Turing test is that a machine can be considered truly intelligent in human fashion if at least 30% of people who are exposed to it believe that they are dealing with a human. A chatbot by the name of Eugene Goostman officially passed the Turing test with flying colors in 2014.
Of course, a chatbot tricking humans into thinking it is a human does not mean that it is, in fact, as intelligent as a human. In Eugene Goostman’s case, “his” cover story was that he was a 13-year-old Ukrainian boy, so he always had an excuse for the (many) glaring screw-ups and inconsistencies in his answers: English is not his first language, and he’s only 13!
What Is Missing From AI?
While many use the terms AI and ML interchangeably, they are not quite the same thing. A bot can be fantastically good (and even better than a human) at anything that it is explicitly trained to do, but it will usually be thoroughly inept at tasks outside of its core programming.
For instance, present a person with some wood and a box of matches, and she will instinctively think of fire. Show or describe the same to an AI, and you will get no such effect.
So far, our approach to AI has been one of brute force:
- Develop ever more complex machine learning algorithms
- Run them using ever more powerful hardware.
However, if you assume that AI should be the same as truly human-like intelligence, your current machine learning-based products fall quite short of that definition in a few significant ways.
For starters, there are a number of other elements that you would expect of human-like intelligence, such as:
Conceptual Learning
For instance, food is anything that goes into the body and is used as fuel. When learning the concept of “food," a human understands that this could include things like a burger with fries in the US, as well as crispy, deep fried crickets in Thailand, even if he himself has never experienced or even heard of the latter.
Arbitrary Goals
Yes, an AI can beat a human opponent in a video game. But a human player could also play, for instance, to only beat a less skilled opponent by a small margin, instead of a crushing victory. Or to play only until they reach an arbitrary score, instead of until the game is won. An AI cannot make these kinds of goal adjustments on the fly. They must be explicitly programmed into it ahead of time.
Creativity
For example, while an AI might be built to know that paperclips are used to hold papers together, it probably won’t be able to figure out that they also make great hangers for your Christmas ornaments. Not unless this exact use for paperclips is explicitly represented in its training data.
Common Sense
When your friend says she went to a restaurant and ordered a steak, she doesn’t need to spell out that she eventually received it and ate it. Common sense allows us to keep communication manageable by not needing to specify every. single. detail.
General Purpose Reasoning
Life always presents us with new situations that you haven’t encountered before. Thankfully, you are able to use analogy and other general frameworks to reason about those new situations. For instance, you can ask yourself if the situation in question bears any similarity to anything else you've seen before, if it is a problem or not, whether or how it might affect you or others, and how you might try to solve it.
Self-Awareness
According to Wikipedia, self-awareness is how an individual consciously knows and understands their own character, feelings, motives and desires.
While most of these are the subjects of cutting edge research in the field of AI, we are not quite there yet. No current AI application is in any way intelligent in a human-conscious way.
Then how come some AI systems seem so uncannily clever?
One particularly uncanny example is Hanson Robotics’ Sophia.
Image Source: AI humanoid concept, Google Images - Yeah, kinda creepy, I know…
There are two simple reasons why Sophia, Eugene and other bots seem so clever:
- They are running highly complex machine learning algorithms
- They have cool-looking user interfaces to gather data and deliver outputs in a user-friendly way
As such, in practice today, artificial intelligence and machine learning refer to the same thing: the replication of certain human analytical and decision-making capabilities. However, even the best AI application currently out there still needs lot of rules and human supervision.
What Are Some Promising Leads in AI Research?
Now that you've seen the progress that AI has made up to this day, let’s take a look at what the future holds in terms of promising AI research.
Reinforcement Learning
Reinforcement learning is an application of deep learning where the only training the algorithm gets is in the form of loose rules that result in rewards and penalties.
For example, the chess-playing AlphaZero used reinforcement learning to teach itself how to play chess. In short, AlphaZero played chess with itself repeatedly, and used the data generated by the game environment to maximize its final score (the reward). In reinforcement learning, there is no labeled data, and human intelligence is only involved in designing the learning environment and tweaking the reward and penalty system to maintain the correct incentives.
Distributed Machine Learning
Distributed machine learning is machine learning done on a distributed computing system to take advantage of highly scalable computing power. As you've seen, in order to get quality predictions from complex machine learning models, substantial training data sets need to be processed. Processing this data on a single machine is a bottleneck, so finding ways to efficiently parallelize the training process is a hot lead in AI research.
- Meta-Learning - is learning about learning. A meta-learning algorithm aims to isolate the rules, protocols and adaptations used in the process of learning when solving for a particular goal.
- Quantum Machine Learning - happens when quantum computing meets machine learning. This includes quantum ML based on linear algebra (the quantum equivalent of classical ML algorithms), quantum reinforcement learning and quantum deep learning.
- Social Machine Learning - Humans are quintessential social creatures. While you learn a lot through raw perception of your environment, you also learn much from fellow humans, by watching them perform a task, or listening them talk about it. In fact, much wisdom and knowledge has been transmitted through generations via stories, fables, cautionary tales, aphorisms, and text books, all created by other human beings. This allows each generation to grow societal knowledge and learning beyond what was achieved by previous generations. But it also allows contemporary people to learn from one another, such that learning in any given field is not done linearly, but in parallel.
What Challenges Face Machine Learning and AI?
Here are the main roadblocks that are holding ML and AI back from widespread adoption:
Correlation Vs. Causation Vs. Explainability
Most mainstream ML applications are black boxes. This is particularly true of deep learning-based applications. Furthermore, there is a gap between correlation and causation in ML. While most of us will have heard the saying that “correlation is not causation," nonetheless most ML techniques - particularly statistics-based ones - rely heavily on data correlations to make predictions.
In contrast, rational humans use logical reasoning to derive causal relationships from facts. Lack of explainability also raises questions about whether a model is aware of both the known and the existence of the unknown when making predictions, instead of basing its output on the assumption that the data it has is a complete and exhaustive representation of the relevant universe.
Explainability is necessary in order for AI-generated models to be trusted and accepted as valid in the real world. After all, you would probably be wary of getting medical treatment based on a diagnosis made by a black-box method, without understanding the facts and process that led to the diagnosis.
Another example is the situation where the explainability of a decision is mandated by law. GDPR, a global privacy law enacted by the European Union in 2016, gives a person the right to an explanation for a decision that was made automatically. As such, it is illegal under GDPR to automatically refuse someone’s application for credit without explaining what caused the refusal.
Finally, there is the matter that human intelligence has been able to decant learning into simple and elegant laws of nature that tend to hold and be reaffirmed in vastly different contexts and circumstances than the ones that generated them. The high complexity and lack of explainability of deep learning algorithms is at odds with the quest of scientific research to find the simple and elegant equations that have been proven time and time again to underpin nature. Will AI ever be able to automate the process of extracting new, previously-unknown-to-us, laws of nature?
Edge Computing
Most machine learning nowadays is applied only after data has been transported considerable distances from its source. Edge computing refers to the ability to process and model data near its source, thereby reducing network and response time latency, and increasing data security.
Insufficient, Poor Quality, Or Non-Representative Training Data
Today, solving simple problems with the algorithms you have requires thousands of examples. Solving complex problems requires millions of examples. On top of that, to be useful, the data needs to be clean and properly labeled. This is a hard problem. Finally, non-representative training data can lead to biased, unusable predictions. In other words, junk in, junk out.
In theory, generalized AI is a carbon copy of human intelligence.
In practice, machine learning has been seeing outstanding success in mastering narrow tasks. Still, replicating human intelligence with a high degree of fidelity remains an elusive goal. While we have yet to see a truly human-like, intelligent and self-aware bot, the perfect should not be the enemy of the good. Modern AI applications are increasingly useful to firms and individuals everywhere. They are automating your most tedious work, increasing our accuracy and sometimes even making possible what was not possible before.
References
(1). Sephora case study

