


Table of Contents
In this article, I'll walk you through how you can add rows to a Pandas DataFrame. I’ll introduce the most popular techniques for this purpose, focusing on how each approach works and in which situations you should use them.
- How to Add Columns to a Pandas DataFrame
- Intro to Pandas: What Is a Pandas DataFrame and How to Create One
While columns in a DataFrame mainly represent features or variables, rows usually represent individual observations or pieces of data. Every row is unique and is defined by the different features or variables in its columns. Knowing how to add new rows to an existing DataFrame is crucial if you're working with data because it allows you to increase the size of your dataset, which in most cases leads to better insights and results from your analysis.
Before diving into the various ways of adding rows to a DataFrame, let's create a simple DataFrame.
import pandas as pd
# Create a dictionary of data
data = {
'StudentID': [1, 2, 3, 4],
'FirstName': ['Emily', 'John', 'Robert', 'Sara'],
'Grade': [90, 85, 77, 92]
}
# Create a Pandas DataFrame from the dictionary
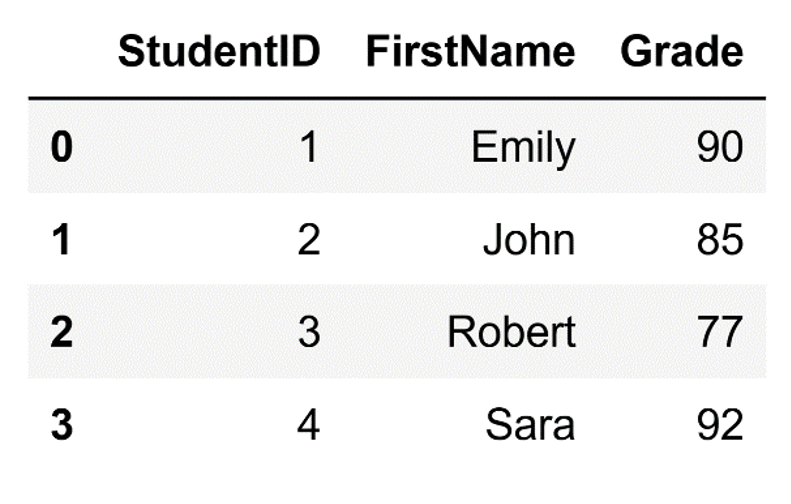
df = pd.DataFrame(data)The DataFrame that we just created looks like this:
The DataFrame.
Image source: Edlitera
Article continues below
Want to learn more? Check out some of our courses:
How to Add Rows Using the .loc Indexer
You can add single or multiple rows to a DataFrame using the.loc indexer. The.loc indexer allows you to select data based on the labels assigned to the rows and columns of your DataFrame. When using.loc, Pandas searches the DataFrame's index for the label you've specified and returns the corresponding row or column. If you specify a label that doesn't exist, an error is raised.
While the.loc indexer is generally used for selecting data already present in a DataFrame, you can also use it to add data to a DataFrame. To add a single row using the.loc indexer, you can specify a new index label and assign it a dictionary containing the data for the new row. This method directly modifies the DataFrame in place.
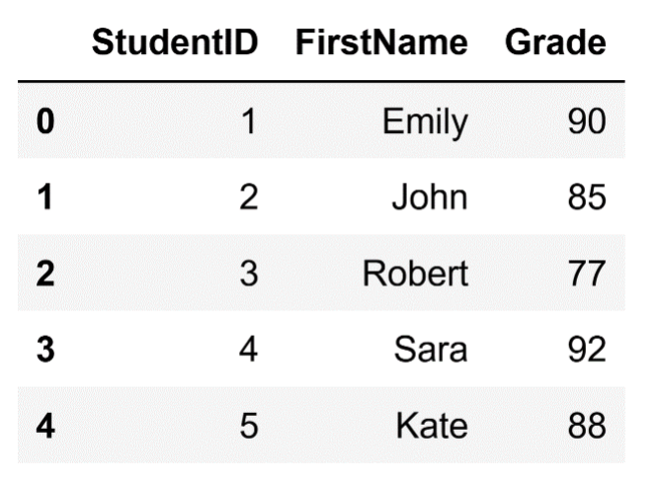
To demonstrate, let's add a single row with the index '4' to our existing DataFrame:
# Add a new row using loc
df.loc[4] = {'StudentID': 5, 'FirstName': 'Kate', 'Grade': 88}Running this code will add an extra row to our DataFrame, so it will now look like this:
Adding a row with the .loc indexer.
Image source: Edlitera
As you can see, I’ve successfully added a new row to the DataFrame. The way this works in the background is pretty straightforward: Pandas first checks whether the index label already exists in the DataFrame. If it does, it will overwrite the existing row. Otherwise, it will append a new row with your provided index label.
This way of adding rows is handy when you have specific, labeled data to add. For instance, if you are maintaining a DataFrame of student records and need to add details for a newly admitted student, using.loc makes it very simple. The.loc indexer is also helpful when updating an existing row based on the index label.
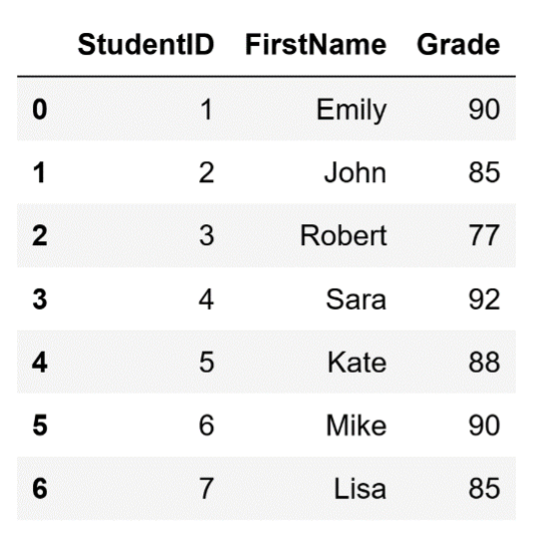
As I mentioned, you can also add multiple rows using.loc. To do so, you need to create a loop that will iterate over a list, where each member of that list is a dictionary:
# Add multiple rows using loc
new_rows = [{'StudentID': 6, 'FirstName': 'Mike', 'Grade': 90},
{'StudentID': 7, 'FirstName': 'Lisa', 'Grade': 85}]
for idx, row in enumerate(new_rows, start=len(df)):
df.loc[idx] = rowAfter running this code, our DataFrame will look like this:
Adding multiple rows to the DataFrame.
Image source: Edlitera
As you can see, this process is a bit more involved and is often clunky to use in practice, so you don't usually add multiple rows at a time using the .loc indexer. Instead, if you want to add multiple rows, you’ll use the concat() function.
How to Add Multiple Rows Using the concat() Function
Pandas's concat() function is often the go-to method for adding multiple new rows to your DataFrame. The way it works is very simple: it takes a list of DataFrames that you want to concatenate and joins them based on their indices, or specified keys, aligning them vertically (row-wise) or horizontally (column-wise). To simplify, it creates a new DataFrame out of the rows you want to add to your original DataFrame and then merges the newly created DataFrame to the existing DataFrame. When using the concat() function, you need to decide whether to reset the resultant DataFrame index or keep the indices of the two original DataFrames.
Because of how the concat() function works, it isn’t well suited for adding single rows: if you wanted to add a single row, you’d need to create a whole DataFrame that holds only that row, which would be highly inefficient. In those situations, using the .loc indexer to add that single row to your DataFrame is a much better idea.
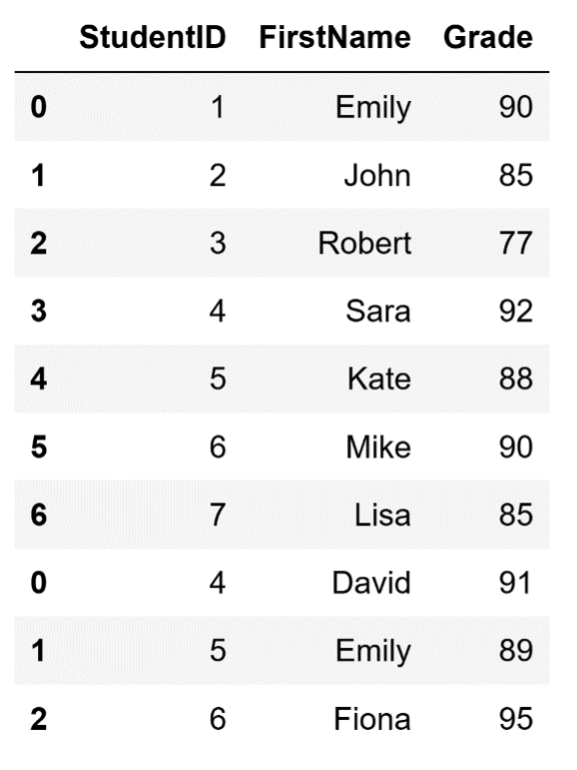
Let's first demonstrate how to add one DataFrame containing two rows to the DataFrame I created at the beginning of this article. In this case, I won’t ask Pandas to reset the index.
# Create additional DataFrame
additional_students = pd.DataFrame({
'StudentID': [4, 5, 6],
'FirstName': ['David', 'Emily', 'Fiona'],
'Grade': [91, 89, 95]
})
# Use the concat() function to combine the new DataFrame
# with our original DataFrame
# Do NOT reset the index
df_students = pd.concat([df, additional_students], ignore_index=False)After running this code, we’ll end up with a DataFrame that looks like this:
Adding multiple rows with the concat() function without resetting the index.
Image source: Edlitera
What happens in the background is quite simple: the two DataFrames are concatenated row-wise by default. The ignore_index=False part stops Pandas from resetting the index, which can lead to problems later on if you try to access rows based on their index because the DataFrame will have duplicates. Because of this, I typically set the ignore_index parameter to True. By resetting the index, you ensure you won't run into duplicates, which can save you a lot of trouble during data analysis.
Let's implement that change in our code:
# Use the concat() function to combine the new DataFrame
# with our original DataFrame
# Reset the index
df_students = pd.concat([df, additional_students], ignore_index=True)After running this code, we will end up with a DataFrame that looks like this:
Resetting the index when using the concat() function to add rows to a DataFrame.
Image source: Edlitera
As you can see, you don't run into any problems this time. There is one more thing you need to remember when adding rows like this: the features of your original data need to match the features of the data you want to add. If you try to add rows that contain more features than your original data, a new column that represents that new feature will be added to the DataFrame.
For example, let's add some new students to our current DataFrame.
# Create a DataFrame that contains new students
new_students = pd.DataFrame({
'StudentID': [4, 5, 6, 7, 8, 9, 10],
'FirstName': ['David', 'Emily', 'Fiona', 'George', 'Hannah', 'Ivan', 'Jane'],
'LastName': ['Doe', 'Evans', 'Fisher', 'Gordon', 'Hall', 'Ivanov', 'Johnson'],
'Grade': [91, 89, 95, 78, 87, 92, 88]
})If you compare this DataFrame of new students with the old one, you will notice that this DataFrame has four columns, not three. The columns in the original DataFrame are 'StudentID,' 'FirstName,' and 'Grade,' but this new DataFrame has an extra column: ' LastName. ' Because the new DataFrame has an extra column if I try to add it to my original DataFrame, I will automatically create a new column in it.
# Use the concat() function to combine the new DataFrame
# with our original DataFrame
# Reset the index
df_students = pd.concat([df_students, new_students], ignore_index=True)After running this code, we will end up with a DataFrame that looks like this:
Adding new data with more features than the original data results in a new column.
Image source: Edlitera
As you can see, because I set ignore_index=True, I’m not running into any problems in the index, but there is a new column in our DataFrame called 'LastName.' Because this column didn't previously exist, the values in it for all the rows of the original DataFrame are missing. This can be a huge problem, so make sure that your new data has the same columns as the existing DataFrame. If not, be ready to handle the newly created columns populated with missing values.
In this article, I’ve explained how to add rows to a Pandas DataFrame. I covered both how you can add a single row to a Pandas DataFrame using the .loc indexer and how you can add multiple rows using the concat() function, focusing on how you perform the two operations and how everything works in the background.

![[Future of Work Ep. 1] Future of Fashion: Using Data to Predict What Will Sell with Julie Evans](https://res.cloudinary.com/edlitera/image/upload/ar_16:9,c_fill,f_auto,q_auto,w_100/56ar4tdmijwmrgnhoq4f56kcoddw?_a=BACADKBn)