






Table of Contents
In Pandas, data manipulation tasks like selection, filtering, and conditional modifications are frequently performed using indexers. Among these, the .loc indexer is pivotal for label-based indexing. This article will explore the .loc indexer, explaining how to use it for selecting data in Pandas DataFrames and Series.
What is the .loc Indexer
We use the loc indexer for label-based indexing in Pandas. This indexer uses the labels of rows or columns to access data. Those labels can be anything, even numbers or timestamps. On one hand, the iloc indexer is particularly useful in situations where the labels we have are unknown or irrelevant. On the other hand, the loc indexer is what we use when we have clearly defined labels that carry some meaning.
The loc indexer is highly flexible, supporting:
• single labels
• lists of labels
• slices
• boolean arrays
Let's demonstrate how we can select data using the loc indexer. For starters, I am going to create a DataFrame that can be used as an example:
import pandas as pd
import numpy as np
# Sample data
data = {
"Name": ["Alice", "Bob", "Charlie", "David", "Eva", "Frank"],
"Age": [25, 30, 35, 40, 45, 50],
"City": ["New York", "Los Angeles", "Chicago", "Houston", "Phoenix", "Philadelphia"],
"Occupation": ["Engineer", "Doctor", "Artist", "Teacher", "Lawyer", "Chef"]
}
# DataFrame creation
df = pd.DataFrame(data)
# Setting descriptive non-integer indices
row_labels = ["first_row", "second_row", "third_row", "fourth_row", "fifth_row", "sixth_row"]
df.index = row_labels
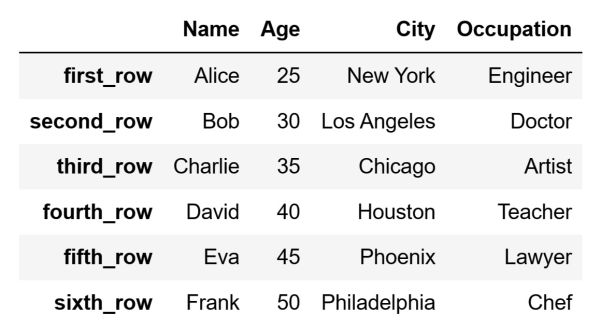
The code above will create the following DataFrame:
As can be seen, the index of our DataFrame is not numbers but instead descriptive indices. In a similar situation, using the loc indexer is way more reasonable than using the iloc indexer.
Article continues below
Want to learn more? Check out some of our courses:
How to Return a Row as a Series
It is frequent to need to access data that is stored in a particular row in your DataFrame. Using loc, we can specify the label of the row in our DataFrame that we want to access. Pandas will access that row, and return it as a Pandas Series object.
For instance, let's return the row that describes Charlie:
# Select the row for 'Charlie'
charlie_row = df.loc["third_row"]
Running this code will return the following Series:
The code above will return a Pandas Series, but not only that. In addition, it will store that Pandas Series in the charlie_row variable so that we can access it later on.
You can certainly select any row in the DataFrame and return it as a Series. This is done if you correctly specify the label connected to that row. If you try to return a row connected to a label that does not exist in the DataFrame, Python will raise an error. For example, if you try to run the following code, it will result in an error:
# Try to access a row
# connected to a label that does not exist
df.loc["100th row"]
If you run the code above, Python will raise the following error:
KeyError: '100th row'This error informs that you are trying to use the loc indexer to access a label that does not exist in your working Pandas DataFrame.
How to Return Multiple Rows as a DataFrame
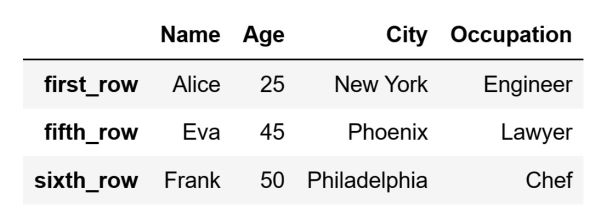
You can also access multiple rows using loc, in the same way that you can access a single row. If you select multiple rows in a DataFrame using loc, what you get back is a DataFrame and not a Series. For instance, let's say that I want to select the rows connected to the following labels:
• "first_row"
• "fifth_row"
• "sixth_row"
To access these rows with the loc indexer I will create a list with these labels. Afterward, I will enter that into the square brackets:
# Access multiple rows
# using the loc indexer
rows_to_access = df.loc[["first_row", "fifth_row", "sixth_row"]]
Because we selected multiple rows, the result is a DataFrame and not a Pandas Series:
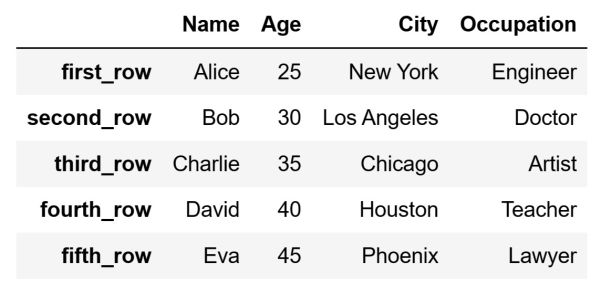
Slices can be employed to select multiple rows in a slightly different manner from typical slicing. To do this, we specify the label of the first row as the start of the slice and the label of the last row as the end. This approach returns all rows from the starting to the stopping row, inclusive of both (in standard slicing where we use row positions the end index specified in a slice is not included in the result).
Let's use the loc indexer to return all of the rows between the row indexed with the label "first_row" and the row indexed with the label "fifth_row", including these two:
# Return a slice of our original DataFrame
slice_of_rows = df.loc["first_row": "fifth_row"]
The code above will store the following DataFrame inside the slice_of_rows variable:
Finally, we can also use boolean values to access multiple rows. To access multiple rows using boolean values, we only need to enter a list of boolean values inside the square brackets when using the loc indexer. When Pandas runs into the value True, it knows it needs to return that row. If it runs into False, it will skip that particular row. Be cautious when using this approach. It will not work unless your list of boolean values is as long as your list of row labels.
Let's use this approach to select the rows connected with labels "second_row" and "fourth_row":
# Select the rows
# connected to the labels
# "second_row" and "fourth_row"
# using a list of boolean values
two_rows = df.loc[[False, True, False, True, False, False]]
The code above will store the following DataFrame inside the two_rows variable:
How to Return a Column as a Series
We can return a column as a Series similar to how we can return a single row. The only difference between the two is that the syntax for return columns is a bit more complex. To put it simply, when you want to return a column you technically need to define that you want to return all of the rows of a certain column. Let's return the values stored inside of the column connected to the index label "City":
# Return the values stored in the column "City"
city = df.loc[:, "City"]
The code above will store the following Series inside the city variable:
Using this approach, we can return any column as a Pandas Series. All we have to do is specify the correct column index value.
How to Return Multiple Columns as a DataFrame
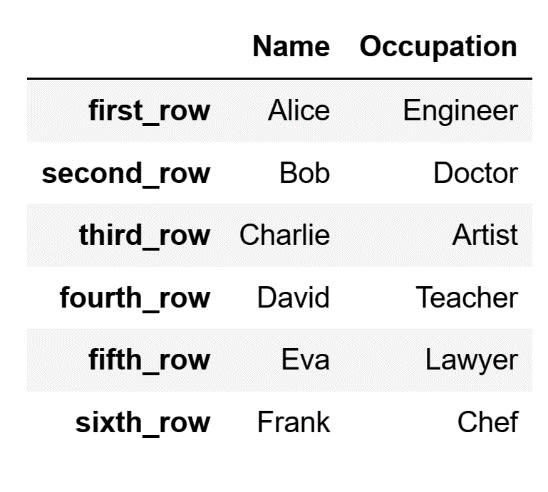
We can also return multiple columns as a DataFrame. To return multiple columns as a DataFrame, you leave the first part of the code as a colon. However, in the second part, you define a list, instead of defining the index of the column you are interested in. For instance, let's return the columns connected to index labels "Name" and "Occupation" using a list of column index labels:
# Return two columns
# using their index labels
name_and_occupation = df.loc[:, ["Name", "Occupation"]]
The code above will store the following DataFrame inside the name_and_occupation variable:
Aside from referencing the column index labels directly, we can also use boolean values similar to how we used them when selecting rows. This is done by entering True and False values instead of column index labels. The code below will produce the same DataFrame that we created a few moments ago:
# Return two columns
# using boolean values
name_and_occupation_boolean = df.loc[:, [True, False, False, True]]
As can be seen, in working with columns, we are somewhat more restricted. This is because we can't use slicing directly and must rely on lists instead. However, this is not a common issue because datasets often have significantly more rows than columns.
How to Return Specific Rows and Columns as a DataFrame
The most advanced way of using the loc indexer is to use it to select certain rows from certain columns. This is something that you will have to do quite often. Selecting only certain rows from some columns is particularly easy. All you have to do is change the first part so that it isn't a colon: but it instead points to the rows you are interested in. For example, to select values from the "Age" and "City" columns in the rows labeled "first_row" and "sixth_row" we run the following code:
# Select the values from the "Age" and "City" columns
# in the rows associated with the "first_row" and "sixth_row" index labels
specific_values = df.loc[["first_row", "sixth_row"], ["Age", "City"]]
The code above will store the following DataFrame inside the specific_values variable:
We can certainly get that identical result using boolean values, by running the following code:
# Select the values from the "Age" and "City" columns
# in the rows associated with the "first_row" and "sixth_row" index labels
# using boolean values
row_booleans = [True, False, False, False, False, True]
column_booleans = [False, True, True, False]
specific_values_boolean = df.loc[row_booleans, column_booleans]
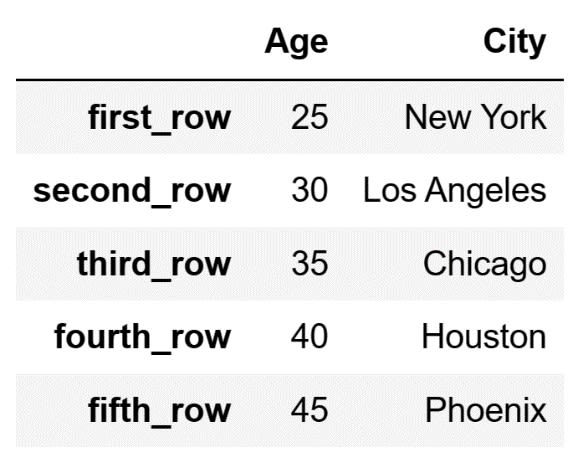
Lastly, we can specify the rows to access using a slice. Moreover, we can pair this with a list of columns to choose particular data from a DataFrame. Let's select all the values from the "Age" and "City" columns, except those from the row indexed with the "sixth_row" label:
# Select all values from the "Age" and "City" columns
# except those from the row indexed with the "sixth_row" label
specific_data = df.loc["first_row":"fifth_row", ["Age", "City"]]
The code above will store the following DataFrame inside the specific_data variable:
- Intro to Programming: What Are Booleans in Python?
- Intro to Programming: What Are Variables in Python and How to Name Them
This article has provided a comprehensive guide on using the .loc indexer in Pandas for data selection. In it, we covered how to, straightforwardly, select single rows, multiple rows, columns, and combinations of these using their labels. The .loc indexer in Pandas, as was explored, is an essential tool for effective data manipulation. Its ability to perform label-based indexing aligns perfectly with the intuitive and flexible nature of Pandas.

