



Table of Contents
It’s easy to get engrossed in all the excitement around what artificial intelligence, or AI, can offer you. Every machine learning engineer will remember the first time they created a model that helped someone. Even people who aren’t specialized in the machine learning field get excited when they find an application that solves other’s problems efficiently (whether they know that AI is used for their solution or not).
While AI is used in a multitude of fields, deep learning research has flourished in some fields in particular. One of those fields is natural language processing, commonly referred to as NLP. Advancements in NLP have made many positive improvements possible within the field of AI. However, in practice, the issue of bias in AI models is a growing concern and is sometimes ignored altogether. Most focus on the benefits brought about by AI technology, but is it possible to responsibly disregard the negative sides of AI?
In this article, I’ll explain how the same biases that exist in society have crept into deep learning models, and whether we can - or should - do something about it.
What is Bias?
These days, bias is mostly mentioned with a negative connotation. In a society that strives for equality, bias toward a person (or group of people) is exactly what we want to avoid. While avoiding personal bias in our lives makes perfect sense, should we apply the same standards to machine learning and deep learning models?
Not so long ago this wouldn't have even been a valid question, but today the situation is different. With the rise in popularity of AI, machine learning and deep learning models have been integrated into to many aspects of our lives. We use AI daily, whether we're aware of it or not, and we regularly use it to shape our own behavior.
For example, each time we use Google's search engine we’re using some form of AI. We often make decisions based on Google search results (ever choose a movie based on Google movie recommendations?). If the behavior of AI in turn influences our own behavior, shouldn't we apply the same human standards of bias to machines? At which point does our AI-influenced “decisions” stop being our own decisions entirely?
If you go to a new city and want to visit the best restaurant, you’ll probably look at reviews that are available online. If the reviews are biased—or if the model that displays the reviews is biased—and you decide to base your decision on those reviews, who’s really making the decision: you or the machine? To add one more question to this list of ideas to explore: do you, as a designer of AI, introduce bias into your models or do the models only seem biased because they prefer one solution over another?
How is Bias Introduced to NLP Models?
The deep learning models most commonly used are mostly "black box” models. In other words, an AI engineer defines a model, compiles it, trains it using some data, and then later uses it to solve a particular problem. Most AI engineers typically stop there. Explaining why a model makes a given decision is not often a problem they tackle. However, this doesn't necessarily mean that the underlying concepts that drive a model are unknown. After all, every model can be explained using mathematical equations.
But what it does mean is that it’s hard to say what a model bases a decision on, so AI designers often don't bother. It's standard practice for supervised learning models, in fact. It's also standard for unsupervised learning models, where the idea of understanding a model's exact decision is even less relevant since the model is learning in an unsupervised way.
Unfortunately, unsupervised learning is the crux of NLP. Natural language processing models are typically supervised learning models, but the data they use is created using models trained in an unsupervised way. This is the case because text is not fed directly into models. Instead, the text is first converted into representations of language that are digestible for models. Those representations are called word embeddings.
What Are Word Embeddings in Unsupervised Models?
Word embeddings are numerical representations of text data created by unsupervised models. A model trained in an unsupervised way scours large quantities of text and creates vectors to represent the words in the text.
Unfortunately, by searching for hidden patterns and using them to create embeddings (which automatically group data), models are exposed to more than just semantic information. While processing the text, models are also exposed to biases that are not unlike the ones present in human society. The biases then get propagated into the supervised learning models—the same models that are supposed to take in unbiased data to ensure that they don't produce biased results.
If you’re skeptical about whether something like this can happen, let’s explore a few of the many examples of racial bias and gender bias that occur in deep learning.
Article continues below
Want to learn more? Check out some of our courses:
Gender Bias in NLP
A 2021 article published by The Brookings Institution’s Artificial Intelligence and Emerging Technology Initiative, part of the series titled “AI and Bias” discusses research into bias and NLP. The article notes a study performed by the author at Princeton University's Center for Information Technology Policy in 2017. The study revealed many instances of gender bias in machine learning language applications. While studying machines as they process word embeddings, the researchers found that the machines learned human-like biases from the word associations in their training material.
For instance, the machine learning tools were learning that sentences that contained the word "woman" more often also included words such as "kitchen" and "art," While sentences that contained "man" more often also contained words such as "science" and "technology." As machine learning picks up on these patterns, these types of gender biases are propagated down the line. If a supervised training model uses biased embeddings, it will also produce biased results.
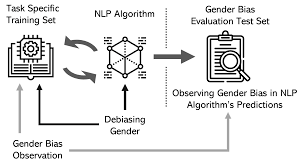
Observation and evaluation of gender bias in NLP.
Image Source: Sun, Tony, et al. "Mitigating gender bias in natural language processing: Literature review." (2019).
In 2015, instances of gender bias were reported in Google Search results. Adrienne Yapo and Joshua Weiss explore this revelation in their 2018 conference paper “Ethical Implications of Bias in Machine Learning." In backlash, Google users discussed their experiences with bias while searching. For instance, mostly images of white males returned when searching for a word like "CEO." The paper also discusses a study that found that the Google Search engine showed more ads for high-paying, executive jobs to males than females.
The best example of gender bias in NLP was found more recently, in May 2020. OpenAI introduced the third generation Generative Pre-trained Transformer, or GPT-3, NLP model. The model was praised as the best NLP model available yet, and able to create language indistinguishable from human speech. However, even the GPT-3 was not immune from gender bias. When prompted to define the gender of certain occupations, the GPT-3 reported that doctors are males and nurses are females. The newest model from OpenAI was released in November 2022, called ChatGPT, and seems to have solved this gender bias problem to a large degree. However, it still makes biased statements from time to time.
Racial Bias in NLP
In a 2017 Princeton study racial bias was observed along with gender bias. The study found that the negative biases on the internet toward African Americans and the Black community remained present in the model embeddings. When examining their model, the researchers found that compared to traditionally White names, traditionally Black names were more significantly associated with words with negative connotations.
This type of racial bias was also demonstrated much earlier than 2017. The Brookings article also cites a 2004 study that found that resumes analyzed by machine learning resulted in resumes with African American names receiving 50% fewer callbacks than those that were characterized by the model as White names.
Does Bias Exist in Other Fields of Deep Learning?
Researchers have recognized cases of bias not only in NLP models but also in other deep learning models (although cases of bias are most prominent in NLP models). Computer vision is another field of AI with no shortage of highly controversial cases of racial bias.
Photo or image recognition is an example of computer vision. In 2015, Flickr’s image recognition tool made headlines when it reportedly tagged a photo of a Black man as an “ape." In a similar instance, Google Photos was also in the public spotlight when it labeled a Black software developer and his friend as “gorillas” in personal photos.
Flickr's infamously mislabeled image of a Black male.
Image Source: Flicker.com
Is AI Bias An Ethical Issue That Can Be Solved?
Knowing that bias exists, the question becomes how to deal with it in machine learning models. What can we do to make ML models as unbiased as possible? Whether we like it or not, word embeddings reflect—to a certain degree—our culture and using them to represent words leads to accurate models. This means that the biases we notice in models exist because they exist in our society. If we want to create unbiased models, their accuracy will undoubtedly suffer. Trying to represent a biased society using an unbiased model will render the model itself useless. On the other hand, biased models and our growing dependence on NLP causes a feedback loop that further accentuates the biases that harm society today.
On paper, it’s an unsolvable dilemma. But maybe we should try to approach it from a different angle: instead of trying to create unbiased models, we should consider applying the same standards to our models that we apply to ourselves. Unfortunately, humans are biased, and if not consciously then subconsciously. Even when we think we're making unbiased decisions, we probably aren’t. As humans, we try to understand and challenge our biased behavior using society’s moral and ethical standards, where an individual's behavior is compared to what is considered acceptable standards of behavior.
So, if we can't prevent making biased decisions, we can create standards in advance to audit them. In doing so, we don’t stop models from making biased decisions, but we can create a method to deal with those decisions before they become harmful. Creating a type of audit mechanism is a possible solution that would allow us to better understand how the behavior of our models might shape public opinion. Looking ahead, we might even create models that specifically work on trying to solve these bias problems. Today, there's the opportunity to start investing more time and money into developing explainable models. Explainable models could lead to big breakthroughs, not only in terms of dealing with biased models, but also in deep learning as a whole.
There are likely many solutions to the bias problem in AI—and not all of them are completely unique and revolutionary ideas. So why isn’t it already standard practice to implement measures to combat bias in deep learning models, and especially in bias-sensitive NLP models? This brings me to the most controversial question of the article: if think you have the solution to bias in models, should you implement it?
Is There a Contradiction Between AI Ethics Vs. AI Use?
In an ideal world, the answer to whether we should use a solution to AI bias is easy. But in reality, many factors are at play between the practical answer and the ethical one. The most important factors are motivation and practicality.
Are companies today motivated to reduce bias in their models? The answer is, unfortunately, a resounding no. The competitive market today doesn't allow for financial “wiggle room," and as companies fight to stay relevant they choose to use the models that produce the best results—even if they’re biased.
Let’s look at this from another angle, and say motivation to reduce bias isn’t a significant factor. Let’s assume that everyone is motivated to de-bias their models as much as possible. This scenario still has problems that need to be addressed. Sometimes it is necessary for models to be biased.
For example, if a company sells boots for men, it’s perfectly logical to create a model with a bias for males. Similarly, if you’re a company selling shoes with high heels, you’ll probably get better results if you bias your model toward females. The overarching theme here? Everything is relative. In some cases, bias is good. In others, it isn’t. Overall, the harder you try the more you will run into convoluted ethical dilemmas. And I haven’t even touched on the ideas around rules of law and morality applying to AI, an object without basic human rights!
The short answer is that there’s not a readily available solution today. The best we can do individually is to try and be less biased ourselves. Because our models mirror society, a group change in behavior will also change your datasets, and one day might create truly unbiased embeddings from which your models can learn.
Is AI Bias Already Too Far Gone to Fix?
The problem with fixing our biased mistakes is that we already heavily rely on the models that we have created in the past. For example, the language model ChatGPT exploded with popularity when it was released, amassing 100 million users in just two months. And while the model is much less biased than previous language models, it still returns biased answers from time to time. ChatGPT’s biased answers are very problematic because a lot of people have completely replaced searching for information online with asking ChatGPT for answers in what they are interested in.
This leads to a very slippery slope. If you search for an answer online with a search engine, you will run into multiple diverse answers even on the first page of the search engine’s returns. However, ChatGPT typically returns only one answer. While this makes it easier to find what you are looking for, because you don't need to go through multiple websites to get an answer, it robs you of the chance to get differing opinions on topics. If everybody uses ChatGPT-like AI models and believe their answers blindly, what happens when the model returns a biased answer? Without being offered a second or third opinion how do you know the answer you get is the objective truth, instead of the biased result of the model answering questions based on the answers it saw in the past?
Suppose a person wants to explore a topic of discrimination based on skin color, gender, or another characteristic, and they encounter a biased statement generated by an AI model that everyone trusts. In that case, they could become trapped in a self-fulfilling prophecy, believing that bias and perpetuating it further as they make decisions down the line. In my opinion, we still have a chance to avoid such a situation, but only if we use advanced AI models with extreme caution. If we don't unequivocally trust what the model returns, but instead make sure to base our opinions by looking at the world around us, we have a better chance of combating bias in AI models.
How Do We Combat Bias in AI Models Going Forward?
AI is already a big part of our lives, and that likely won’t change in the future. On the contrary, its role in our lives is becoming steadily more significant. AI models choose the news you're exposed to each day, and the ads you'll see first each morning. To disregard the ethical implications of leaving something as influential as AI models unchecked is a mistake and leads to questionable results, like the examples of bias in this article.
At times, censoring models seems like the only logical thing to do. However, we often find that using AI as a scapegoat only serves to hide the truth that society is biased no matter how much we try to censor it. The models we train learn simply and efficiently through examples. So, if you see your models making biased decisions, most likely, we as humans are the example to blame. The models only know to simulate what they've been taught, so with models as our mirror we see the flaws in our own reflection that we don't want to see.
In the end, we can use that mirrored reflection to fix our own biases. The real solution to dealing with bias and ethical problems in AI models is to solve those ethical problems within ourselves. Fixing ourselves keeps the high-level accuracy of our models while correcting for bias. Now is the time to begin leading by example for a better future with AI, instead of covering up our past bias mistakes.

