



Table of Contents
As machine learning (ML) gains traction, and quickly becomes a technology that every company wants to implement, those same companies start becoming aware of the challenges that come along with it. Among the challenges: creating and training a machine learning model is a lot simpler than actually deploying and using that model in a practical way.
As mentioned in the famous paper "Hidden Technical Debt in Machine Learning Systems," creating a model is only a small part of the whole picture. The infrastructure required to efficiently use a machine learning model in production is vast and complex. To come straight to the point: it often takes a lot more effort to deploy a machine learning model to production and use it effectively than it takes to develop it.
This leads to my current observation: the focus of a company shouldn't lie only on improving the speed at which new models are created, but also on making the process of deploying the models to production faster and smoother. Of course this does not mean that optimizing models should be neglected. Model training is an essential part of machine learning. The speed at which you can deploy models doesn't matter if the quality of those models is subpar.
However, given the fact that many companies already have competent data scientists and machine learning engineers working on improving the models, the competitive edge will often be achieved through two avenues: better / more data and better / faster model deployment.
What is DevOps?
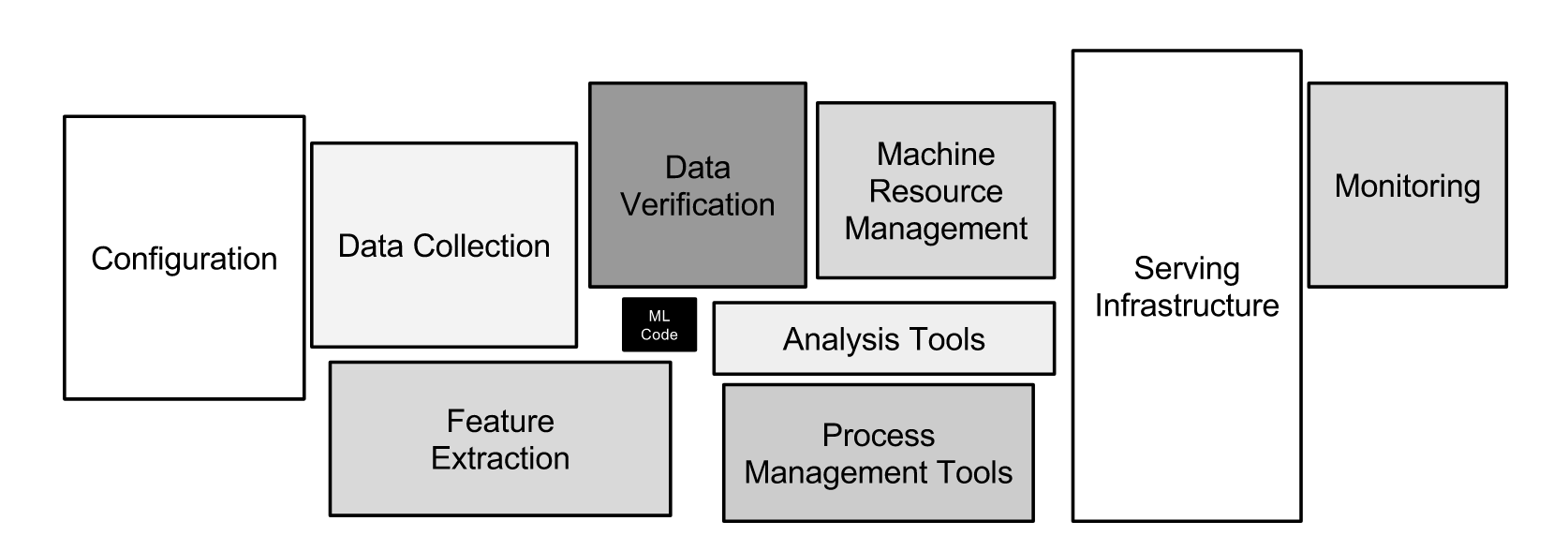
Image source: https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
DevOps (Developmental Operations) might seem like the perfect candidate for machine learning model deployment. After all, the set of practices known as DevOps has been used for some time to reliably and continuously ship software to production systems in very short periods of time. Those practices were originally introduced to complement Agile software development and you can trace several aspects of DevOps back to Agile methodology.
The main goal of DevOps was to shorten the development life cycle and to provide continuous delivery of new features without compromising software quality. Using concepts such as automated building and testing, continuous integration and continuous delivery, DevOps can reduce the gap between developers and IT operations. DevOps has proven to be a great asset to many organizations. By relying on different tools to automate processes and create necessary workflows, it is possible to abstract away the complexities of software deployment and free up developers' time. This leads to a significant increase in productivity.
Two very important concepts in DevOps are continuous integration (CI) and continuous delivery (CD). Let's explain how CI and CD work to shine light on why they proved to be so valuable in increasing developer productivity:
What is Continuous Integration (CI)?
CI consists of sharing a code repository across teams. Developers contribute (integrate) their own code features into a master branch that represents the latest version of the software. Each such integration is verified through the use of automated tests and automated builds, which are then deployed either to a QA system or, in some cases, directly to the production (live) system.
What is Continuous Delivery (CD)?
CD is the practice of developing software in short cycles. By producing code in short cycles you make sure that software can be reliably released at any time. Software is built, tested and released at greater speed and frequency. Developing software in shorter cycles also reduces the complexity of merging the work of various teams. In a continuous delivery system, you should always implement small, incremental changes, which are easy to code-review and easy to revert, if necessary.
However, applying standard DevOps principles such as CI/CD alone won't enable you to accelerate the machine learning life cycle for one simple reason: the field of machine learning consists not only of code, but also, very importantly, of data. Every machine learning model behaves differently depending on the data you feed into it. This is true not only when you train your models, but also at run time: models behave differently depending on the input data you feed them at prediction time. So while you can control the changes in your code, you have less control over changes in the data, since you get it from real world sources, often outside of our control.
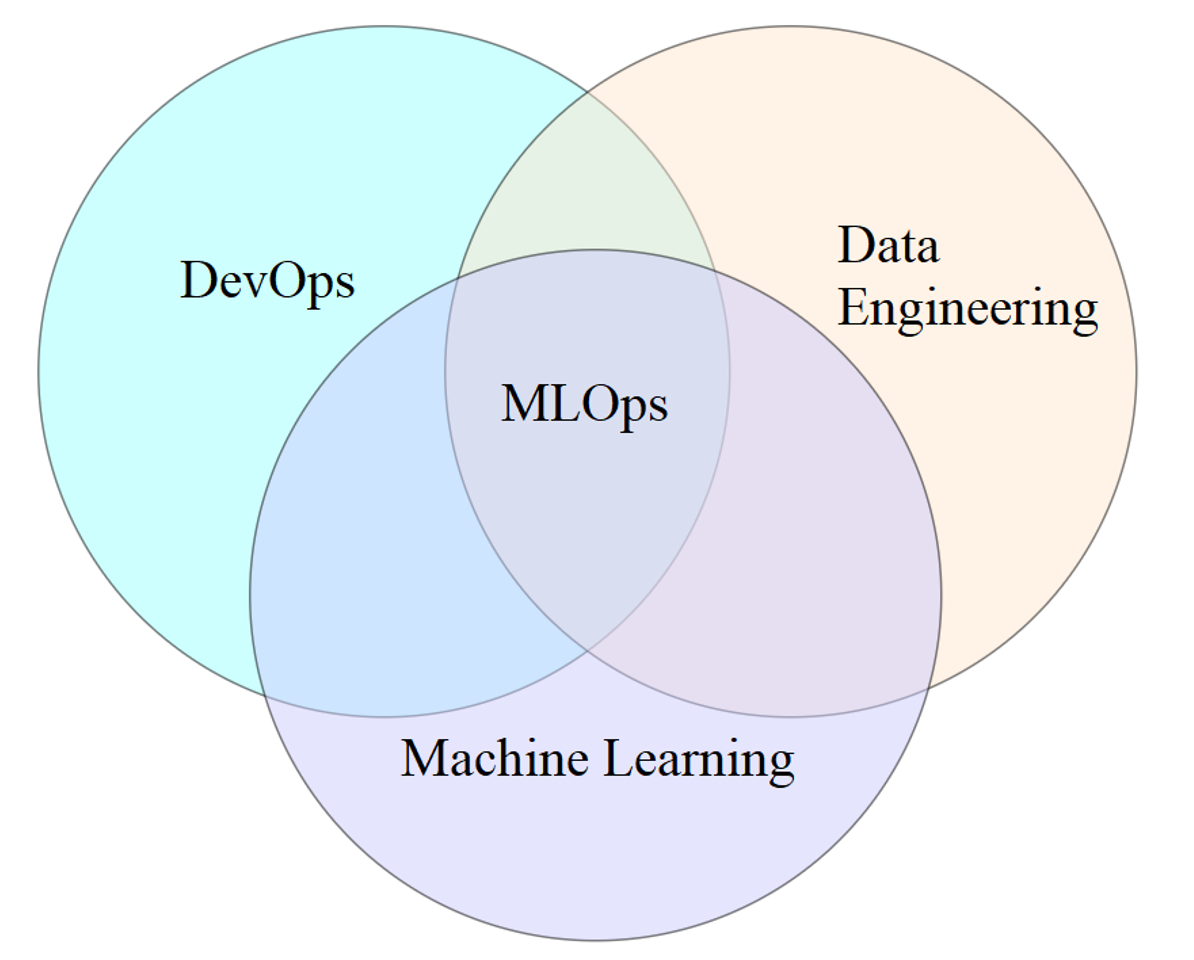
In addition to data and code, you must not forget about data engineering. Instead of focusing on analysis or experimental design, data engineering aims to create and maintain scalable systems for collecting, transforming and storing data into formats that enable further analysis and machine learning. Combining machine learning with some standard DevOps practices, and adding data engineering into the mix you arrive at your solution for managing and accelerating the machine learning process life cycle: MLOps.
MLOps is a combination of DevOps, Data Engineering and Machine Learning
Image source: "MLOps - Machine Learning as an Engineering Discipline", Towards Data Science, Breuel Cristiano
MLOps, as a set of practices, needs to address the main differences between machine learning models and standard software systems in terms of:
- Development
- Testing
- Deployment
- Production Environment
A typical machine learning project requires cooperation between software developers, data scientists and, sometimes, machine learning researchers. While data scientists and machine learning researchers possess skills necessary for exploring data, creating machine learning models and experimenting with said models, they may lack the skills necessary to build production-level services. This is where software developers come in.
In addition to requiring a variety of skill sets, successfully deploying machine learning models must also take into account the fact that machine models degrade over time. That is to say, after some time, all models inevitably begin to perform worse. To maintain good service quality, models need to be retrained and redeployed when they start degrading. This complicates MLOps in two ways: first, because you need to have the right pipelines to easily retrain, revalidate and redeploy machine learning models, and secondly because you need to track summary statistics and monitor the performance of the deployed models to determine when it is time to retrain them.
One very important thing to remember is that ML models decay faster and in more ways than conventional software systems. Taking all the points above into account, here's a list of the required steps needed to successfully launch machine learning model to production:
- Data Extraction
- Data Analysis
- Data Preparation
- Model Training
- Model Evaluation
- Model Integration and Validation
- Model Deployment
- Model Monitoring
Looking at these steps, you realize that MLOps, unlike DevOps, requires two additions alongside continuous integration and continuous deployment. These are:
- Continuous Training (CT) - which is the process of automatically retraining and serving models
- Continuous Monitoring (CM) - which is the process of monitoring production data metrics and model performance metrics
By adding continuous training and continuous monitoring to the mix, you can handle all three types of changes that affect the machine learning development life cycle:
- Changes in data
- Model changes
- Code changes
At the moment, it is still relatively hard to completely automate the machine learning life cycle. It is also often not needed. Teams can choose to perform some steps manually and only focus on automating some of the steps. Over time, they can increase the level of automation.
Generally, the level of automation defines the maturity of the machine learning process and speaks to the ability of the organization to quickly adapt to changing data or business requirements. When the level of automation is high, teams can easily retrain models on new data or train completely new models on the data they already have, thus unlocking more value.
By looking at the level of manual work required, machine learning systems can be separated by level of automation into:
- Fully manual systems
- Automatic ML pipelines without automatic CI/CD pipelines
- Automatic ML pipelines with automatic CI/CD pipelines
What Are Manual Systems in MLOps?
Manual systems are the easiest to get started with and typically do not require specialized MLOps knowledge. However, these systems can break easily and are not recommended at scale. In addition, because they lack automation, such systems make it very hard to train and deploy models that can adapt to changes fast enough.
What Are Automatic ML Pipelines Without CI/CD Pipelines?
These systems are a step up from the fully manual systems. They can work fine if new versions or implementations of the machine learning pipelines are not deployed frequently (they only manage a few such pipelines). When teams don't intend to experiment with many different machine learning models often and wish to deploy new models mostly based on new data, this level of automation can be sufficient.
What Are Automatic ML Pipelines With CI/CD Pipelines?
Finally, systems that include not only automatic machine learning pipelines, but also automatic CI/CD pipelines allow data scientists to rapidly iterate and explore new ideas, leading to significant productivity growth. As I mentioned, this level of automation is preferable, but not always needed.
Unlike DevOps, MLOps is still in its infancy so it requires that teams use a combination of tools, each better suited for some of the steps in the machine learning life cycle. MLOps also still often times requires human supervision, regardless of the level of automation.
Nonetheless, this relative immaturity of the field does not mean that there aren't already tools out there that teams can use to handle different parts of the machine learning life cycle. Quite the contrary. Let's look into some of the more popular ones.
Why Are MLOps Tools Important?
To understand which tools are popular, and why, you need to separate them based on what problems they solve. As mentioned earlier, because of how relatively new the field of MLOps is, most companies use a combination of tools. I will not mention all of the available tools here - the list is too long to fit inside one article. However, I will give a short overview of the most popular ones and what they can be used for.
Generally speaking, MLOps tools can roughly be grouped by the problem they solve. Therefore, there are tools for:
- Versioning
- Orchestrating runs
- Tracking experiments and organizing the results
- Tuning models
- Serving models
- Model monitoring
What Tools Are Used for Versioning?
Article continues below
Want to learn more? Check out some of our courses:
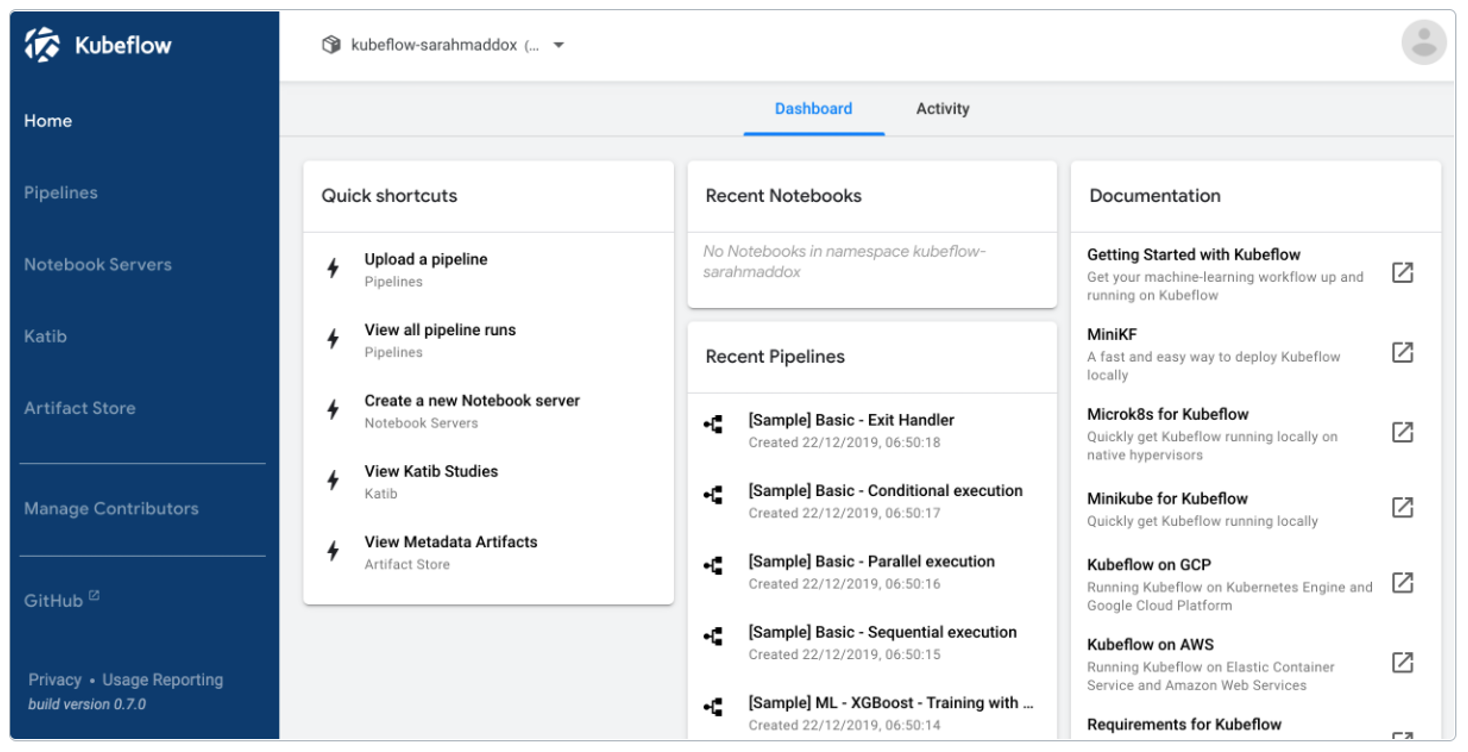
Kubeflow
A tool for versioning data and pipelines, Kubeflow is becoming more and more popular as it matures. It is known as the toolkit for doing machine learning on Kubernetes. It leverages the power of Docker containers and simplifies scaling machine learning models. It also makes it easy to orchestrate runs and deploy machine learning workflows.
Kubeflow is an open-source toolkit consisting of a set of compatible tools and frameworks that facilitate solving various machine learning tasks. While it is held back a bit by the fact that it is relatively new, it is fast becoming the preferred solution for large companies doing machine learning at scale.
Features of Kubeflow include:
- Built for Kubernetes
- Extremely good scalability
- Open-source
- Pipelines can be used with Kubeflow or even as standalone components
- Good UI
- Includes notebooks which offer an SDK (Software Development Kit) to interact with the system
Image Source: Kubeflow, https://www.kubeflow.org/
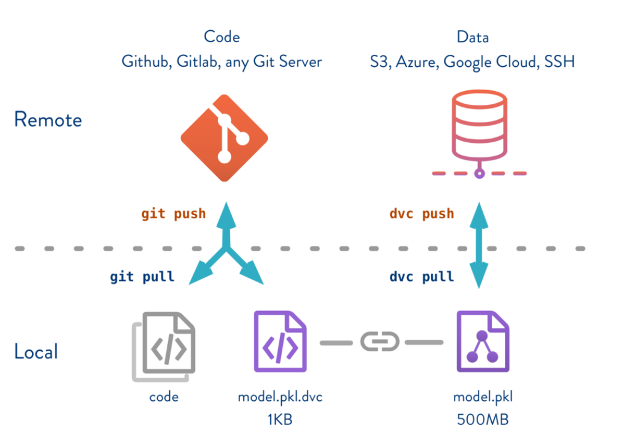
DVC
DVC is an open-source version control system primarily aimed at machine learning and data science. Its goal is to make machine learning models reproducible and to simplify the process of sharing models between data scientists. The main benefit of DVC is that it works regardless of which language you choose to use.
Along with data and pipeline versioning and management, it can also track experiments (to a certain degree). In practice, DVC works as a data pipeline building tool with some easy options for data versioning.
Features of DVC include:
- Language and framework agnostic
- Open-source
- Effective even for large amounts of data
- Storage agnostic
- Tracking metrics
- Tracking failures
- Can build DAGs (Directed Acyclic Graphs) and run full pipelines end-to-end
Image Source: DVC, https://dvc.org/
An alternative to Kubeflow and DVC include:
What Tools Are Used for Orchestrating Runs?
Kubeflow
I already mentioned Kubeflow earlier, so I won't describe it again. However, it is important to know that Kubeflow is also one of the premiere tools for orchestrating runs. In fact, Kubeflow pipelines can be used to overcome many different DevOps obstacles.
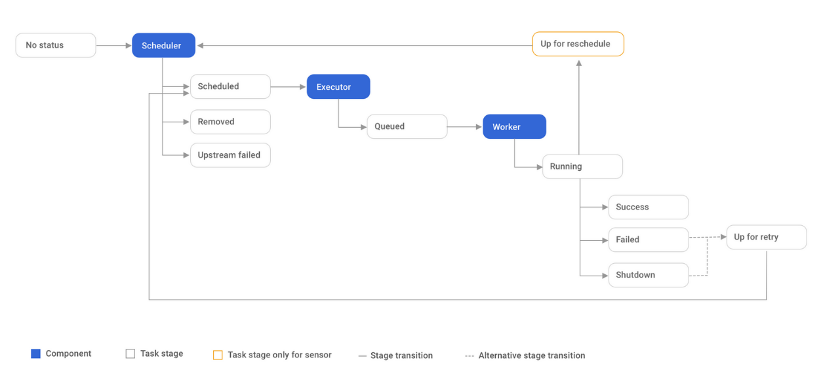
Airflow
Apache Overflow is an open-source project backed by Apache, and written in Python (although it can use any language). It is a platform that can be used for creating, scheduling and monitoring workflows. Those workflows are then monitored using a web application. It has a multi-node architecture based on a scheduler, worker nodes, metadata database, a web server and a queue service. Airflow uses DAGs to manage workflows.
Features of Apache Airflow include:
- Easy to integrate with different infrastructures
- Extensible, scalable, modular
- Models workflows as Directed Acyclic Graphs (DAGs)
- Allows dynamic pipeline creation
Image source: Apache Airflow, https://airflow.apache.org/
Alternatives to Kubeflow and Apache Airflow include:
What Tools Are Used for Tracking Experiments and Organizing Results?
MLFlow
MLFlow is an open source platform that aims to encompass the entire machine learning life cycle. It tackles automation by separating it into four parts, going from raw data all the way to model deployment. MLflow also prides itself in being one of the more popular platforms and it was made by the creators of Spark. Currently, MLflow consists of the following components:

Using MLflow tracking, teams can easily track experiments and organize results. The tool itself has a simple to use UI. It allows users to log and query experiments using Python, REST, R, and JAVA APIs.
Features of MLFlow include:
- Lightweight and narrowly defined package
- Versatile, though somewhat limited
- It requires other components (it has no native support for feature engineering, data pipeline development or pipeline orchestration)
- Easy collaboration on remote or local environments for both individuals and teams
- Library agnostic
- Suitable for both teams and individuals
Comet
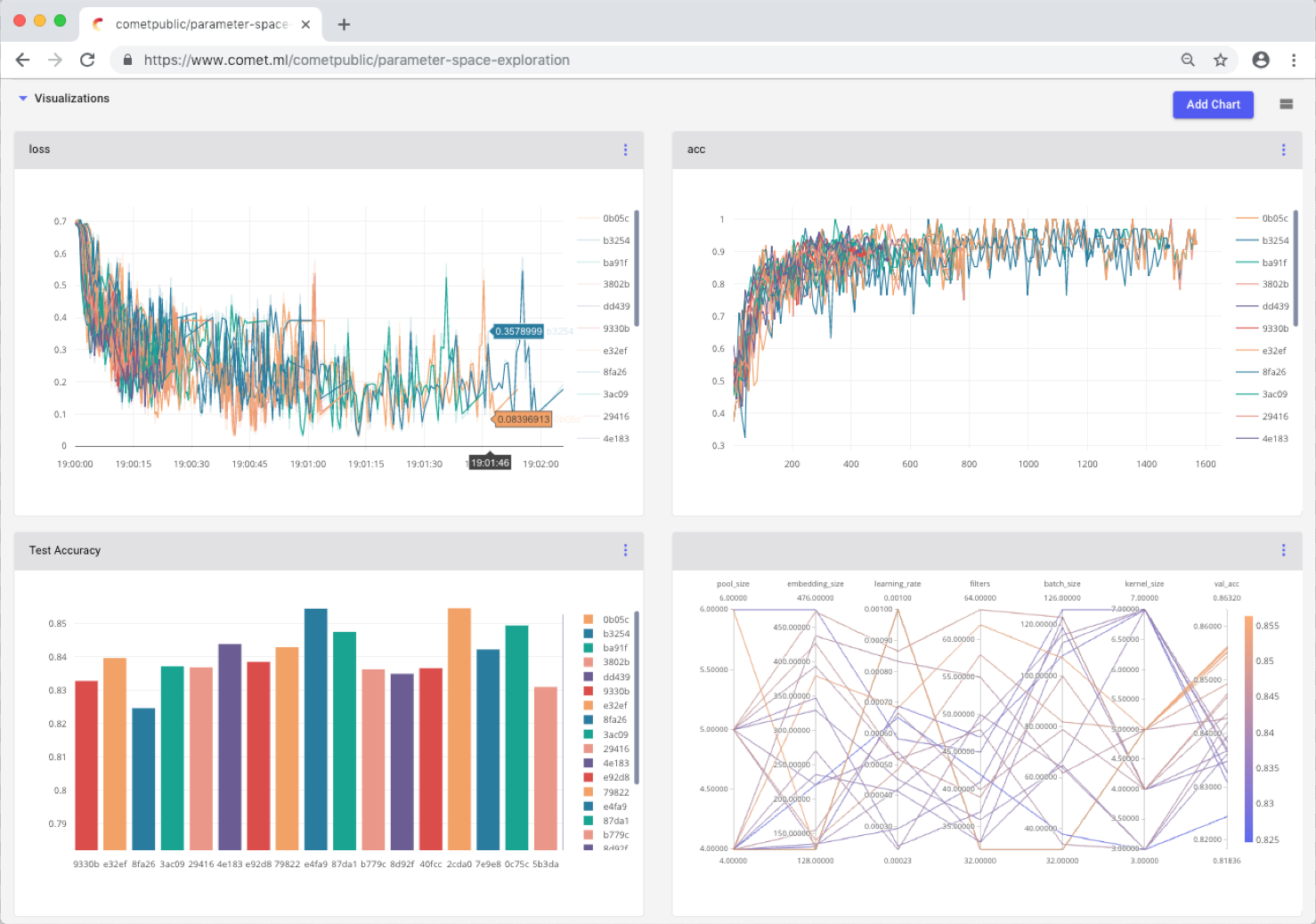
Comet is a self-hosted meta machine learning platform that was built to enable tracking of machine learning projects. It provides the ability to easily compare experiments and keep a record of the collected data and it works with many different machine learning libraries. Comet is easy to use for both individuals and teams alike and, in fact, it can be integrated with a single line of code.
At its core, Comet facilitates experiment tracking. Many different statistics are tracked and saved so they can be compared later. It can track code, dependencies, hyper-parameters, predictions, system metrics and more, which helps users decide which machine learning model will serve them best. In addition, Comet can be used for debugging. It has dedicated modules for audio, vision, text and tabular data.
Features of Comet include:
- Works with a lot of existing machine learning libraries, a lot of different integration options
- Enables detailed experiment tracking (tracks metrics, predictions, hyper-parameters etc.)
- Runs in the cloud, on servers and in a hybrid environment
- Debugging (i.e. identifying issues with data, overfitting, making custom visualizations, etc.)
Image Source: Comet, https://www.comet.ml/docs/user-interface/
Alternatives to MLflow and Comet:
What Tools Are Used for Tuning Models?
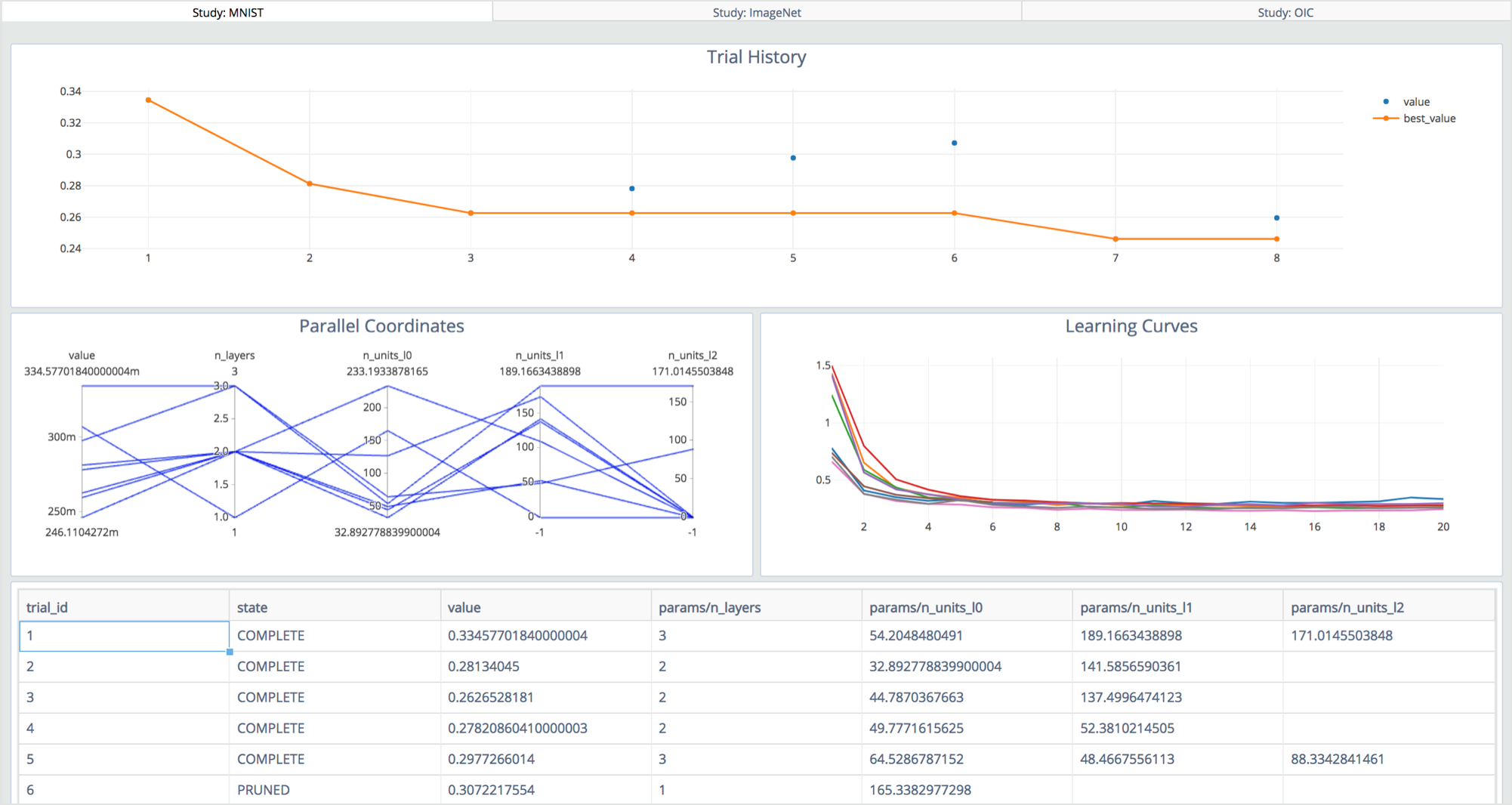
Optuna
Optuna is a tool used for hyper-parameter tuning that integrates with popular machine learning libraries such as PyTorch, TensorFlow, Keras, FastAI, scikit-learn, XGBoost and others. It automatically searches for optimal hypera-parameters using Python. Optuna also provides the ability to prune unpromising trials to get good results faster. It also supports easy parallelization when searching for the best hyper-parameters.
Features of Optuna include:
- Lightweight and versatile
- Platform agnostic
- Pythonic search spaces
- Supports distributed training
- Has powerful visualization options
- Supports a large number of pruning methods
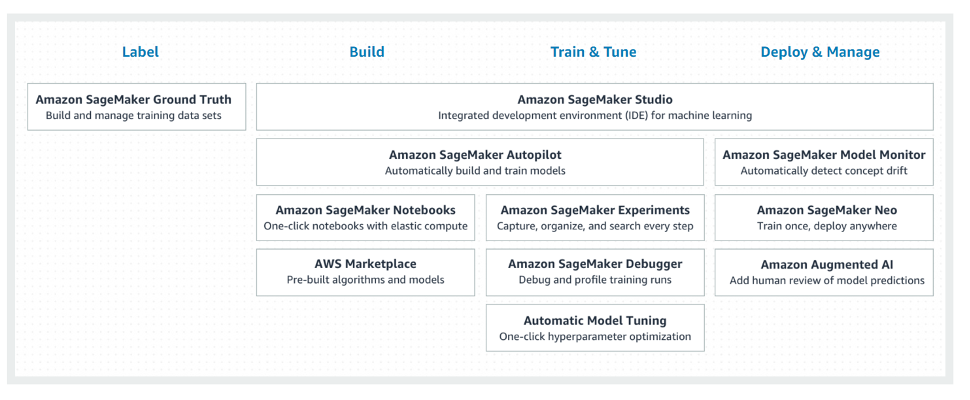
Amazon SageMaker Auto Tuning
Amazon SageMaker's Auto Tuning is an automatic model tuning module offered by Amazon SageMaker. The only thing it needs to work is a model to tune and training data. It supports efficient optimization of very complex models and datasets through parallelization at a very large scale. Another great benefit is that it provides Jupyter notebooks as a common interface, which simplifies configuration and visualization of results.
Features Amazon SageMaker includes:
- Automatic
- Does not have a lot of requirements; just data and a model
- Allows parallelization on a large scale
- Support for Jupyter notebooks
Image source: Amazon SageMaker, https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning.html
Alternatives to Optuna and Amazon SageMaker’s Auto Tuning:
What Tools Are Used for Serving Models?
MLFlow
MLFlow Model Serving allows models to be served via REST endpoints. These REST endpoints are automatically generated and updated, allowing data science teams to have complete control over the entire machine learning life cycle.
Features of MFlow are:
- Can serve model via REST endpoint
- Good when needing predictions at low latency (e.g. in response to user action on a website, in an app, etc.)
Kubeflow
Kubeflow can also be used to serve machine learning models. It is a very flexible tool that can manage almost every aspect of machine learning experiments. Since I have already covered it earlier, I won't insist on it too much here. However, I do need to mention that, although Kubeflow has its own model serving service, at the time of the writing of this article (late 2020), that service is still in beta.
In addition to this beta service, there are a number of additional different services you can use, which provide integration with Kubeflow:
- Seldon Core Serving
- BentoML
- NVIDIA Triton Inference Server
- Tensorflow Serving
- Tensorflow Batch Prediction
Keep in mind that things change very fast in the world of machine learning. Considering the speed of its growth, I believe that Kubeflow will get to the point where it can handle most steps of MLOps on its own relatively soon.
Seldon
Seldon is an open-source platform that allows the deployment of machine learning models on Kubernetes. It can manage, serve and scale models in any language. Seldon can create pipelines that handle model serving, management, and governance. It simplifies model deployment with options like canary deployment.
Features of Seldon include:
- Can be used not only for model deployment but also for model monitoring
- Simple
- Framework agnostic
- Includes explainers
- Not free :(
Image source: Seldon, https://www.seldon.io/wp-content/uploads/2019/06/core_stack.png
Alternatives to MLFlow, Kubeflow, and Seldon:
What Tools Are Used for Model Monitoring?
Amazon SageMaker Model Monitor
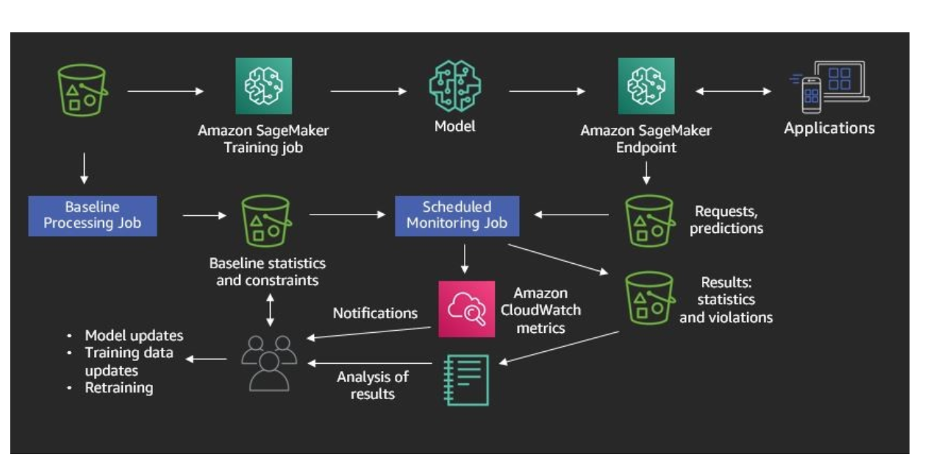
Amazon SageMaker Model Monitor is part of the Amazon SageMaker platform. Amazon SageMaker allows not only monitoring, but also building and deploying machine learning models. For monitoring, SageMaker captures a fraction of the data sent to the endpoint that serves the models and stores it in an Amazon Simple Storage Service (S3) bucket. That data can then be used as part of a monitoring schedule, which will kick off data processing jobs at regular intervals. These data processing jobs will use the collected data sample to compute statistics which can then be compared with the model performance baseline to determine the level of model decay.
Features of Amazon SageMaker Model Monitor include:
- Automatic, easy to use
- Can create a monitoring schedule which generates reports at regular time intervals which can identify model decay
Cortex
Cortex is an open-source model deployment platform. It supports different kinds of machine learning models (Tensorflow models, sklearn models, etc.) which it can expose via automatically scalable APIs. Cortex can also monitor API performance and track predictions.
Features of Cortex include:
- Open-source model deployment platform
- APIs can be written in Python
- YAML can be used to configure infrastructure
- Handles traffic surges with request-based autoscaling
- Integrates easily with any data science platform and CI/CD tooling
Alternatives to Cortex and Amazon SageMaker Model Monitor:
Similarly to how DevOps influenced standard software life cycles and resulted in significant productivity increase, MLOps will influence machine learning life cycles and significantly improve your ability to quickly deploy and scale ever more powerful models. At the moment, MLOps is only just starting to evolve. It is not something new by any means, but it still needs time to mature. As I mentioned, while using MLOps could prove to be a big win (especially for larger companies), using a combination of manual and automated steps is also possible.
Transitioning to a fully automated machine learning life cycle is harder than it might seem at first, and should be done incrementally. Although there are a number of tools on the market, it is hard to say which tools will prove superior in the long run. Currently, most companies use an array of different tools, combining them to create a stack that allows them to handle the various parts of the machine learning workflow. As I've shown in this article, the tool choices vary, and are often influenced by the existing knowledge and infrastructure available to a company or team.
Because of how relatively new MLOps is, especially when compared to DevOps, for example, the best practices are still emerging. As more time passes, some tools will likely rise above others and become best-in-class solutions for the various challenges presented by machine learning workflows. For now, the best thing a company can do is survey the landscape of available tools and create stacks that best suit its needs, with the understanding that next year, or two years from now, a better, simpler, more scalable solution may become available. This should not scare teams away from trialing the various tools available. If you want to learn more about this, check out our Intro to MLOps with MLflow course. After all, the field of machine learning itself is fast accelerating and change is the nature of the game.

