




Table of Contents
The ability to merge data efficiently is a fundamental skill in data analysis. Before analyzing data, it is common to bring data together from different sources into a single dataset. This combined dataset provides a foundation for valuable analysis and insights. This article will cover the main ways on how to merge data from multiple sources in Pandas. This is done by using the four most popular types of merges.
Why Merge Data
The information you need to evaluate is often distributed across different places. Take, for example, assessing the current year's performance of a retail chain. To conduct a thorough analysis, you must first merge the data from each store into a single comprehensive set. Thus, mastering the skill of efficiently merging data is crucial for extracting meaningful insights from it.
There are four common types of merges we use to combine data from different sources. These merge operations are highly similar to join operations in SQL. To be more precise:
• Left Merge (Similar to a SQL Left Join)
• Right Merge (Similar to SQL Right Join)
• Inner Merge (Similar to SQL Inner Join)
• Outer Merge (Similar to SQL Full Join)
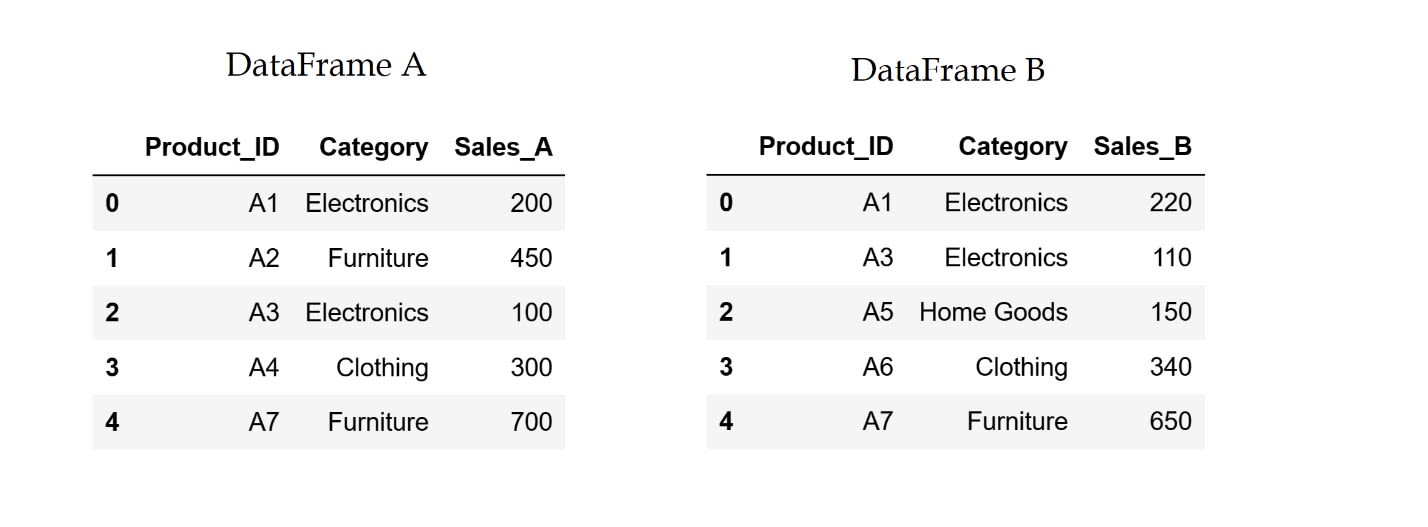
To demonstrate how we perform these operations, let's create two simple DataFrames.
import pandas as pd
# Data for store A
data_a = {
'Product_ID': ['A1', 'A2', 'A3', 'A4', 'A7'],
'Category': ['Electronics', 'Furniture', 'Electronics', 'Clothing', 'Furniture'],
'Sales_A': [200, 450, 100, 300, 700]
}
# Data for store B
data_b = {
'Product_ID': ['A1', 'A3', 'A5', 'A6', 'A7'],
'Category': ['Electronics', 'Electronics', 'Home Goods', 'Clothing', 'Furniture'],
'Sales_B': [220, 110, 150, 340, 650]
}
# Create the DataFrames
df_store_a = pd.DataFrame(data_a)
df_store_b = pd.DataFrame(data_b)
The code above will produce the two following DataFrames:
Once these two DataFrames are ready, we can demonstrate how to perform the different types of merges.
- Intro to Pandas: What is Pandas in Python?
- Intro to Programming: What Are Different Data Types in Programming?
Article continues below
Want to learn more? Check out some of our courses:
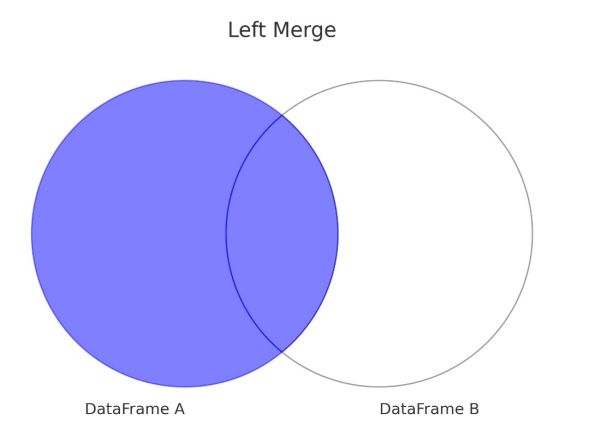
How to Do a Left Merge
The Left Merge, known in SQL as a Left Join, is an operation that returns all rows from the left DataFrame and the matched rows from the right DataFrame. This merge operation aligns records from the two DataFrames based on common key columns. Another way could be to identify and include all records from the left DataFrame, along with the matched records from the right DataFrame, if available. When the right DataFrame is missing a corresponding record, the result will contain NaN for the missing columns.
In practice, a Left Merge is particularly useful when you have a primary dataset that must remain intact. However, you still need to add supplemental information from another dataset. For example, let’s say you have a list of products that your store offers (left DataFrame) and a list of monthly sales data (right DataFrame). In this case, you can use a left merge to attach sales data to the product list. This ensures that you maintain a complete list of products, regardless of the availability of sales data for each product. In scenarios where data completeness of the primary dataset is crucial, the left merge is the go-to method. Using a left merge helps to identify records in the primary dataset that find matches in the secondary dataset. This can be essential for data completeness checks, data cleaning, or preprocessing tasks before further analysis.
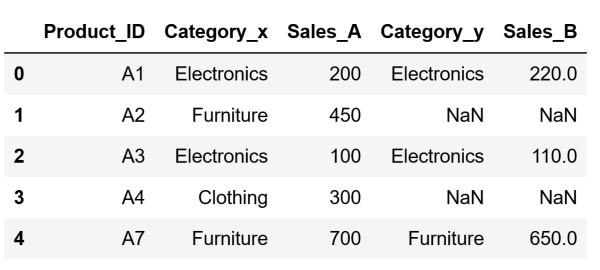
Let's perform a Left Merge. We will define df_store_a as our primary DataFrame. Here we want to add data from the other DataFrame. This will result in all records from df_store_a to be included in the merged DataFrame left_merged_df. The data from df_store_b will be added where it matches df_store_a based on the Product_ID column. If there is no matching Product_ID in df_store_b, the resulting left_merged_df will still maintain all the records from df_store_a with NaN in the columns that would instead have data from df_store_b.
# Perform a left merge
# using "df_store_a" as the main DataFrame
left_merged_df = pd.merge(
df_store_a, df_store_b,
on='Product_ID',
how='left'
)
After running the code above, our DataFrame will look like this:
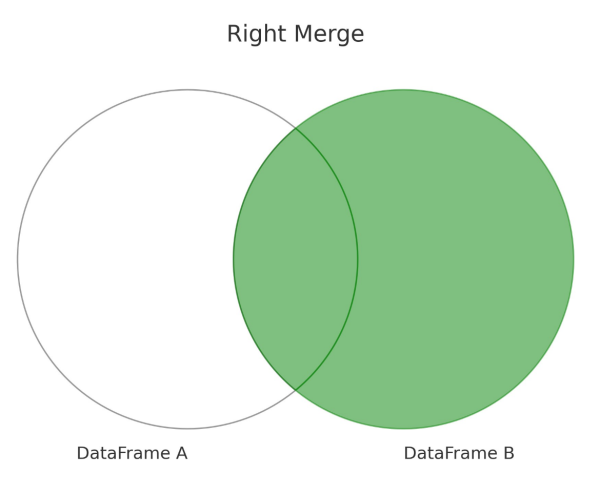
How to Do a Right Merge
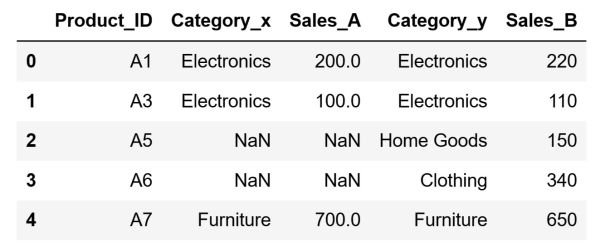
The Right Merge, known in SQL as a Right Join, is similar to the left merge but with the roles of the DataFrames reversed. It returns all rows from the right DataFrame and the matched rows from the left DataFrame. When there is There might be cases when there is no match in the left DataFrame for the right DataFrame's records. in the left DataFrame, This would result in the resulting DataFrame that will display NaN in the columns originating from the left DataFrame.
The Right Merge is useful in situations where the completeness of the right DataFrame is more important than that of the left DataFrame. For instance, if you're working with a dataset of completed transactions (right DataFrame) and want to enrich it with additional product details (left DataFrame)., In such cases, a right merge would ensure that you keep all transactions while bringing in any available product details. Choosing between performing a Left Merge and a Right Merge often depends on the dataset designated as the primary dataset for analysis.
The importance of preserving a complete dataset depends on the individual It's a matter of perspectives. as to which dataset is considered more important to preserve in its entirety. In most cases, you can achieve the same result can be achieved with either a left or right merge. This can be done by swapping the DataFrames and choosing the appropriate merge operation.
Let's perform a Right Merge. We will use df_store_b as the primary DataFrame. To do so, we can use code that is nearly identical to the one we used when performing the Left Merge., The difference will be that except this time we will set the value of the how argument to "right". By doing so we will create a new, merged DataFrame where all of the entries from df_store_b will be present. Moreover, the data from df_store_a will appear alongside it when corresponding matches based on Product_ID are found. Entries from df_store_a that are missing do not have a matching Product_ID in df_store_b will not appear in the resultant DataFrame.
# Perform a right merge
# using "df_store_b" as the main DataFrame
right_merged_df = pd.merge(
df_store_a, df_store_b,
on='Product_ID',
how='right'
)
After running the code above, our DataFrame will look like this:
- Intro to Pandas: What is a Pandas DataFrame and How to Create One
- Intro to Pandas: How to Create Pivot Tables in Pandas
How to Do an Inner Merge
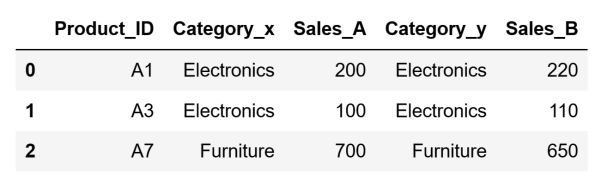
An Inner Merge, similar to an Inner Join from SQL, combines the DataFrames based on common keys and returns only those rows with matching values in both DataFrames. Unlike the left and right merges, the inner merge focuses on the intersection of the two DataFrames. In other words, any records without a match in the other DataFrame are excluded from the final result.
The Inner Merge is the default merge operation in Pandas and is similar to the intersection of two sets in mathematics. It's beneficial when you want to find similarities between datasets. For example, when analyzing the performance of products that are present in two store inventories (represented by two DataFrames), an inner merge provides a DataFrame consisting only of the products that are available in both stores.
These types of merges are often used in data analysis to combine datasets with a high level of confidence. This process helps exclude data that may not align between the datasets. This can be essential for analyses that require a high level of data integrity and where the presence of unmatched records might affect the final results.
Let's perform an Inner Merge. In the inner merge, there is no concept of a "primary" DataFrame. Thus, both DataFrames have an equal role. The DataFrame we get by performing an Inner Merge will only consist of the rows that have a matching Product_ID in both df_store_a and df_store_b.
# Perform an inner merge
inner_merged_df = pd.merge(
df_store_a, df_store_b,
on='Product_ID',
how='inner'
)
After running the code above, our DataFrame will look like this:
How to Do an Outer Merge
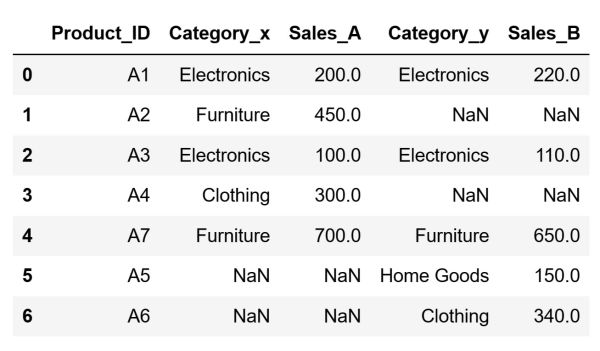
The Outer Merge, similar to a Full Join in SQL, combines all rows from both DataFrames, aligning the rows based on common keys. Moreover, it includes all records from both the left and right DataFrames. Where there are no matches, the result will have NaN for the missing data. This type of merge is equivalent to the union of two sets.
An Outer Merge is useful when you need a complete picture of both DataFrames, including the similarities and differences. For instance, let's say your task is auditing the product listings from two different store branches. In this case, an Outer Merge would allow you to see which products are sold at both locations, which are exclusive to one location, and which are missing from the other. This type of merge is the most inclusive merge operation and is essential for comprehensive exploratory data analysis.
Let's perform an Outer Merge. In the Outer Merge, similar to the Inner Merge, there is no primary DataFrame. The final DataFrame will have all the data from both df_store_a and df_store_b, filled with NaN for any missing matches. This way we ensure that no data from either DataFrame is lost in the merge process.
# Perform an outer merge
outer_merged_df = pd.merge(
df_store_a, df_store_b,
on='Product_ID',
how='outer'
)
After running the code above, our DataFrame will look like this:
This article offered an insightful analysis of each one of the four different types of merges. It explained how to perform the specific merge, and what happens in the background. In addition, the article provided examples of situations where it's useful to use that specific type of merge. Mastering the diverse ways of merging data in Pandas is important for handling different datasets and extracting valuable insights from them.

