


Table of Contents
MLOps, or Machine Learning Operations, is a combination of Machine Learning (ML), DevOps, and Data Engineering that streamlines the ML development lifecycle. It allows organizations to automate and scale the deployment of machine learning systems in production.
In this article, I will discuss how MLOps integrates the various aspects of DevOps processes in machine learning, the different use cases where it applies or why it is needed, the key skills and tools required to implement it, as well as best practices and future trends.
What is the Difference Between DevOps and MLOps?
DevOps is a combination of development and operations in software engineering. It aims to streamline the software development lifecycle for continuous integration and delivery (CI/CD), automating and optimizing deployment pipelines for increased speed and reliable releases.
The same principles apply to MLOps, integrating data workflows and machine learning models into the existing DevOps pipelines, while differentiating data and model management from the standard software release cycle. As data volumes grow rapidly day-to-day, MLOps demands a more modular, flexible, and experimental approach to managing the frequency of changes in production.
Key Differences Between DevOps and MLOps
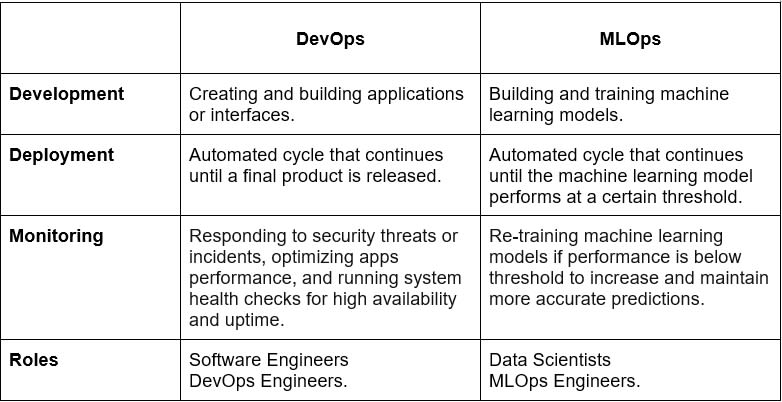
Why Do You Need MLOps?
Many industries today attempt to implement machine learning models and workflows in their operations and processes. However, not all of them make it into production or get into the hands of end-users.
MLOps bridges this gap and addresses the challenges in the operationalization and deployment of production-ready machine learning models. By adopting the MLOps approach, organizations can benefit from several positive aspects to stay relevant and grow with this tech into a data-driven space.
The following list highlights the various benefits of applying the standard practices of MLOps and how it helps solve the most common problems in managing ML models:
Benefits of MLOps
- Seamless integration of ML models and datasets with software applications, as well as unifying the release cycles.
- Reduced technical debt, missing components, and inefficient workflows by enabling automated testing across ML models, artifacts, or outputs from training.
- Ease of deployment, automatic scaling, and migration of ML models to the production environment.
- Effective management of the end-to-end machine learning lifecycle, from data processing, analysis, up to deployment and monitoring.
- Reliable infrastructure and resource management system, process, and control.
- Adoption of agile principles and best practices to machine learning projects, enabling better collaboration between IT operations and data science teams.
What Are the Skills Required for MLOps?
MLOps is fundamental to any individuals or businesses who want to deploy machine learning solutions in an efficient and scalable way. As MLOps become a rapidly growing field, there’s been a massive increase in demand for machine learning and artificial intelligence roles. With the intersection of data science, machine learning, and DevOps, MLOps engineering has emerged as a new role that specializes in productizing, operationalizing, and deploying machine learning projects.
What Tools Are Used in MLOps?
With the growing need to implement machine learning workflows in organizations, there are several MLOps tools that are made available today to help automate and scale ML pipelines more effectively and efficiently.
I will mention only a few of the most popular MLOps tools here, but more of these tools will be covered in other related articles in this series:
Article continues below
Want to learn more? Check out some of our courses:
MLflow
MLflow is an open-source platform, developed by Databricks, for managing the machine learning lifecycle. It is scalable, extensible, and platform-agnostic by design, enabling it for use with different machine learning libraries (such as TensorFlow, PyTorch, XGBoost) and programming languages (such as Python, Java, and R) that also features a lightweight API-first framework. For more information on using MLflow for MLOps.
Kubeflow
Kubeflow is an open-source project, built on top of the Kubernetes platform, for developing, deploying, and managing portable ML workflows. It aims to simplify and scale machine learning models and deploy them into production by leveraging the diverse, modular, and extensible tooling and technologies available in Kubernetes.
Apache Airflow
Apache Airflow is an open-source scheduling and monitoring platform wherein workflows are defined as a code for easier maintenance and scalability. Apart from the dynamic, extensible, and lean configuration as code of pipelines, it also features a rich user interface for visualizing running pipelines, monitoring progress, and troubleshooting issues in production.
Amazon SageMaker
Amazon SageMaker is a fully managed service for building, training, and deploying machine learning models and MLOps workflows built on Amazon Web Services (AWS). It features integrated development environments with no-code visual interfaces for ease of use and scalability that helps accelerate ML development, automating and standardizing the end-to-end machine learning lifecycle. To know more about Amazon SageMaker in-depth.
Neptune
Neptune is a metadata store for MLOps that provides a single place to systematically capture and manage model registry and experiment tracking. It helps keep track of all datasets, parameters, code, metrics, charts, and other ML metadata in an organized way for easier maintenance and reproducibility, enabling teams to be more productive on ML engineering and research.
What Are Best Practices for MLOps?
With each project, it is important to set up and track data in the correct way for best results. Here are some MLOps best Practices:
Acquire Legitimate Sources of Data
Like any type of project, the first and most important step is getting the right information. Similarly, knowing the use cases or problems that the project aims to solve helps the organization map out the goals and actions needed to implement it. This serves as the definition phase where data teams must know what data to collect and where to get them, ensuring that the source of data is legitimate and readily accessible.
Furthermore, as data grows and changes overtime, organizations must establish efficient and effective ways to manage them. Data labeling is considered one of the best practices to ensure that the datasets are validated and interpreted with the most accurate meaning and context. By applying this process, organizations can determine the size of work, frequency of churns, and possible risks early in the development, hence saving time and resources later in the process.
Track Experiments
As patterns of data change constantly, it is crucial to continuously test and experiment multiple machine learning models while keeping track of the results. Combining experiments for code, datasets, features, ML models, and hyperparameters produces metrics that help data scientists track performance and compare results using any available tracking tools such as Neptune, Comet, and MLflow.
Additionally, some factors may alter the results of experiments depending on the environments and outcomes of the project. Hence, it is also important to keep track of the changes in ML models by storing and versioning them using model registries. A model registry functions the same way as Git or SVN versioning, which makes the code (or models) reproducible without having to recreate them from scratch.
Automate ML Pipelines and Monitor Model Performance
Before MLOps was introduced, machine learning tasks were performed manually, which caused inconsistencies and unnecessary human errors. To address such challenges, it is critical for organizations to implement automation in all areas of the MLOps cycle.
Nowadays, a lot of open-source technologies (TensorFlow, MLflow, OpenShift, etc.) are built and developed continuously to help automate the end-to-end machine learning process, from data preparation, model development, up to testing and deployment.
As data changes frequently over time, it is essential to have a continuous retraining process put in place. Automating MLOps pipelines is a complex problem to solve, however one of the best practices is to set up a scheduled trigger service when the system detects new data streams or performance degradation, thus initiating model retraining with less manual intervention.
Establish Infrastructure Reliability and Code Quality Checks
Most organizations want to save cost and speed up time to deployment, without compromising quality. Aligning MLOps practices with business needs and regulatory requirements may become difficult to tackle, and thus overlooked. Oftentimes, the lack of structure in the infrastructure and systems where these areas operate causes bottlenecks in which ML models fail to streamline.
ML systems require not only a reliable deployment platform, but also extensive and robust automated testing. This way, problems in features, data, models, and infrastructure are discovered in the early stages, allowing you to fix errors prior to integration and deployment.
What Are Future Trends of MLOps?
As ML projects grow more in demand, future advancements are being developed for MLOps. Here are some examples of the upcoming trends:
Data-Centric Approach
Fundamentally, it is important for data science teams to have a strong foundation in understanding data models. However, with growing complexity and volume of data, it is equally important to balance good models with the right data, and therefore expand their understanding on the social and business context of data.
As future trends demand transitioning from a model-centric to data-centric approach in handling ML operations, it is essential to find systematic and iterative ways to improve data quality. For instance, breaking down data into smaller chunks with consistent labeling may produce more accurate results when training models, which therefore requires constant cleaning up and updating of data while keeping the code/model fixed.
Data Drift Detection
Good data means data that is defined consistently. As time passes, real world data changes constantly, hence, causing discrepancies in the accuracy of predictions. Knowing what data to track and distributing them purposely across the MLOps environments (such as development and production) can significantly improve how sudden shifts in data and performance are handled.
One example of detecting potential issues with data drift is by monitoring ML model performance and customizing alerts that send notifications on any significant changes in real-time. This way, an immediate response can lead to possible solutions without delay and prevent errors.
AI Observability
While monitoring focuses on viewing and comparing systems performance data (past and current), observability shows why systems performance will change relative to time and the various conditions affecting it.
In other words, with observability enabled by AI, organizations can proactively detect model performance issues and interpret patterns that can identify the root cause of failures and resolve unforeseen problems more quickly. For widely distributed data ecosystems, it is critical to see all the components and interrelated environments across datacenters, offshore facilities, supply chain, and edge. Keeping track of data at this scale may require “hyper automation” to enable precise model performance and self-retraining as soon as data changes (input and output) are detected.
MLOps Change Management
In machine learning systems or any applications that involve data, security often becomes a high risk as data can be easily passed on digitally across environments if not handled properly. While building a cohesive and unified MLOps system, where production data can be used repeatedly for experiments, it is crucial to establish a framework for handling data securely.
As data changes occur very frequently, incorporating a feedback loop from production back to data collection, and retraining into the MLOps life cycle, allows a more effective way to manage the changes. In this case, it becomes necessary to implement a two-phased approach in production, in which live data (customer-facing) is stored separately from production data that is used for experimentation and model retraining.
To become successful in implementing MLOps, it is important to know the main points on why it is needed, how it integrates with existing IT operations, what roles are needed for your team, and what tools to use. Knowing the best practices and future trends of MLOps can you’re your organization sustain and scale any machine learning projects more effectively.

